複数のWebサービスを運用するSREチーム立ち上げの背景
自己紹介
はじめまして! メタップスホールディングスでSREマネジャーを務めている山北です。 過去にベトナムでのオフショア事業立ち上げからアプリケーション開発に携わっており、メタップス入社後はクラウドインフラにも徐々に関わりつつ、最近ではsrestというSRE向けのサービスの事業責任者を兼任しています。
複数サービス運用における課題
メタップスでは複数の自社サービスを運用していますが、SRE組織が立ち上がるまではサービスごとに開発者が専任で所属し、バックエンドエンジニアが開発の傍らインフラ構築や運用を兼任している状況でした。 そのため、組織として以下のような課題がありました。
- ナレッジの共有不足
- サービス単位でチームが分断されており、インフラの設計手法・運用などのナレッジが共有されにくい。
- 効率化の問題
- 開発優先となるため、インフラ運用の最適化やチューニング、構成のアップデートなどは後回しになりがちとなる。
- オンコール対応は属人化し、復旧手順のマニュアル化や自動化が追いつかない。
上記のような課題を解決するべく、SREチームの立ち上げが決定しました。
SREチーム立ち上げの背景
SREチームを立ち上げるに当たって、単体サービスは勿論、全てのサービスをSREチームが横断的に運用出来るよう、以下のような体制を構築しました。
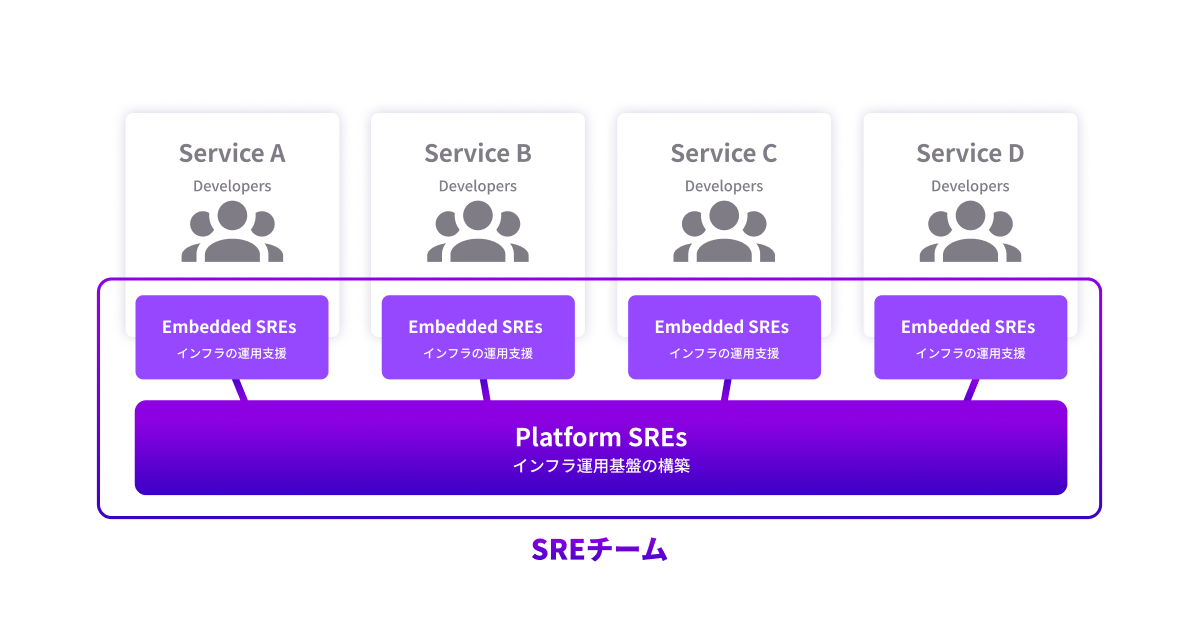
- Platform SREs インフラ基盤の構築や開発体験の向上をミッションとし、横断的に利用可能なプラットフォームの設計・開発を推進する。 サービス共通のプラットフォームとなるAWSの設計やコード化 (IaC)、CI/CD整備、ログ基盤の構築などを行う。
- Embedded SREs サービス開発に参加し、開発チームと連携してシステムの安定運用・サービスの信頼性向上に取り組む。 Platformチームが開発したインフラ基盤フレームワークを各サービスに展開。開発チームから上がった要望対応や、共通化できる仕組みをフレームワークに組み込む。
SREチーム発足後に生じた課題
SREチームを立ち上げたことにより当初の課題は改善されましたが、SREの活動を行っていく上で、複数サービスという特性上、新たに以下のような課題が発生しました。
- SREチームが運用するサービスが増えるにつれて、Slackの参加チャネルが増え続け、システムのアラートを取りこぼすケースが増えた。
- 障害発生時はAWSをはじめ、SlackやDatadogといったツールをいったりきたりする必要があり、時系列で何が起きていたかトレースしづらい。
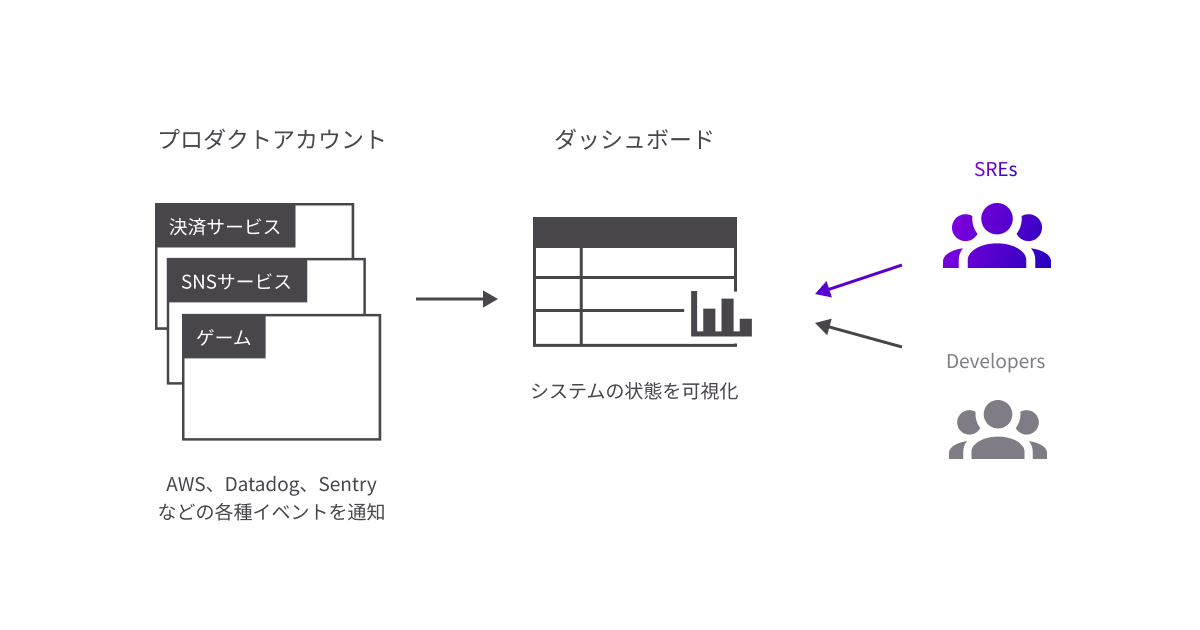
こうした課題を解決するために現在、SREチームではダッシュボードの開発に取り組んでいます。
現在のSREチームの取り組み
上記であげた発足後の課題を踏まえて、Slackの通知を見逃した場合でも、大きな障害に繋がらないよう日常的に異常が発生していないか確認できる仕組みを構築することにしました。 それがSREチームが日常的に監視できるダッシュボードの開発です。
具体的には、AWSやDatadog、Sentryなどから通知されるイベントログを集約する仕組みを構築し、SRE・開発メンバーは、複数サービスが一元管理されたダッシュボードを確認することで、システムのどこで問題が起きているかをすぐに把握することが出来る仕組みとなります。
ダッシュボードの構築により、SREメンバーは毎朝自分が担当するサービスのアラートチャネルを追いかける必要がなくなり、ダッシュボードでアラートのサマリーを横断して確認できるようになりました。
また定例ミーティングにおいては、以前はSlackからアラートを遡ってディスカッションを行っておりましたが、現在は各サービスごとの課題をダッシュボード上で全て一元可視化しながらディスカッションを行うことが出来るようになり、時間的にも効率化されました。
SREチームを立ち上げたことによって、以下のようなメリットと効果を感じています。
- クラウドネイティブに適した設計手法や運用、セキュリティといった様々なナレッジが集まるようになった。
- サービスを横断した組織となり、安定したインフラ基盤を提供できるようになった。
- 会社全体を通してサービスごとの課題を可視化できるようになった。
- 開発チームは実装に集中できるようになった。
終わりに
SREの取り組むべき課題は多岐に渡りますが、複数サービスの運用となると、技術的な側面だけでなく、開発組織の文化に変革が求められます。 この変革を実現するためには、組織全体で共有されるビジョンのもと、チーム間のコミュニケーションを強化し、知識と経験を積極的に共有する文化を築くことが不可欠になると思います。。