自動テスト可能なインフラプロジェクトの設計について
自己紹介
そもそも自分は SRE の仕事がどのようなものなのか実はよく分からない。
もちろん SRE と連携して開発を行う機会は常にあるので、あくまで外から見た感想くらいなら言えるが、個人的には SRE をゴールキーパーのようなものだと勝手に思っている。
同じチームながらフィールドプレイヤーとは異なる役割を持っていて、味方への指示出しから組み立てへの参加もすれば、今際の際での大仕事(致命的なバグをビッグセーブ or 終わらない障害対応という名の失点)を見せてくれるポジションだとサッカー中継を見ていてそんなことをいつも思い浮かべている。
なお開発側である自分とは仕事へのアプローチや考え方は異なるかもしれないが目指すところは一緒で、それはチームの勝利、すなわちシステムに安定と継続的な発展をもたらすことであると信じている。
そしてシステムの品質を恒常的に維持・向上させるために一番重要なものは何かと問われたら、自分はソースコード全行に対してテストを簡単に実施できる開発環境を構築することであると答えたい。
そこで今回はプロダクトを構成する各レイヤの中でも 1、2 を争うほどにテストが難しいインフラの領域で、よりテスタブルなインフラ開発を実現するためのプロジェクト設計について話をしたいと思う。
なお SRE Magazine は本来 SRE の話題を専門に扱う媒体であるのに対して、個人的に SRE はインフラ軸のエンジニアがアサインされることが多いからという強引なこじつけでこの記事の投稿をゴリ押ししたのだが、それでも投稿を許可していただいたしょっさんさん並びに SRE Magazine 編集局の方々には、ここで改めて感謝を述べておきたい。
テスタブルなインフラプロジェクト
アプリケーションの開発ではプログラム言語を問わずテストコードを実装するための仕組みがほぼ例外なくサードパーティあるいはビルトインで提供されている一方で、インフラの開発においてはテストコードを実装するための仕組みがあまり一般的には普及していないというのが個人的な印象である。
もちろんアンテナ感度の高いインフラエンジニアならだいぶ昔からインフラ開発においてテストコードを用いたテストを実践していたのかもしれないが、自分の場合は Terraform がビルトインでテストコードの実行機能を提供し始めたのがテスタブルなインフラプロジェクトの設計を始めたきっかけとなる。
なお SRE でもなければそこまでインフラエンジニアでもない自分が、無い知恵を強引に詰め込んで約半年かけて設計した Google Cloud + Github Actions ベースのインフラプロジェクトは以下のようなものになった。
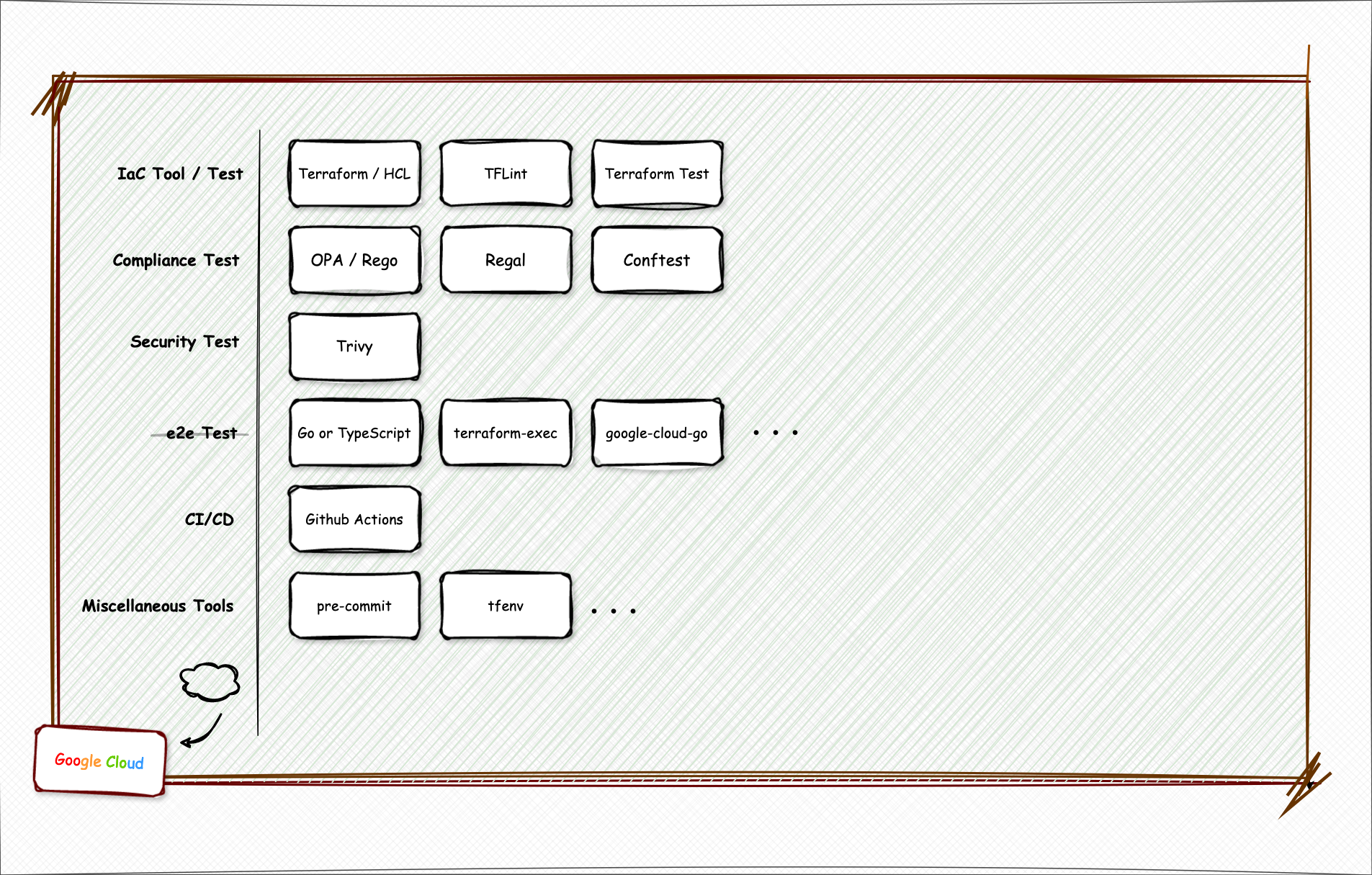
上記ツールやフレームワークを用いたテスト設計についてはこれから説明を行っていくが、プロジェクトの実装サンプルは Github 上で公開しているので、もし興味がある方はぜひ覗いてみていただきたい。
(なお現時点では e2e テストなどの一部機構は未実装となっている)
また設計の全過程と実装の解説は全てブログにドキュメンテーションしてあるので、こちらも併せて読んでもらえれば嬉しい限りである。
(ただし文庫本換算で 500 ページ以上の文章を読む覚悟を突然要求してくる点には注意していただきたい)
それでは早速このインフラプロジェクトのテスト設計について詳しい説明を、といきたいところだがまずその前にインフラのテストコードが実行可能なプロダクト環境は通常とはやや異なる点について説明しておく必要がある。
プロダクト環境
世の中の Web プロダクトは一般的に本番環境(prod)、staging 環境(stg)、開発環境(dev)といった環境を用意して運用や開発が行われているかと思う。
しかしテストコードを実行可能な開発環境を構築する場合においては、その常識にやや手を加える必要がある。
インフラテスト界隈のさまざまな設計を参考につつ、最終的に自分のプロダクト環境は以下のようになった。
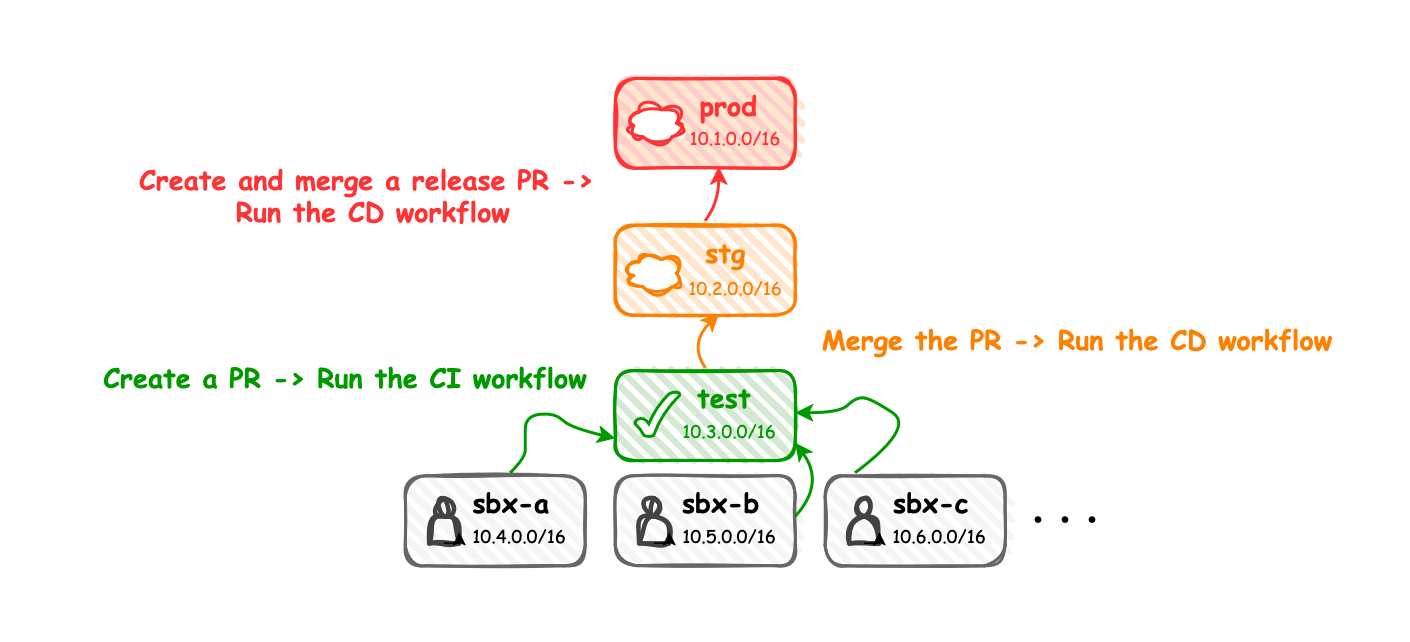
prod 環境や stg 環境は通常の意味通り、本番運用環境と本番ローンチ前の動作確認環境をあらわしている。
一方で sandbox(sbx) 環境や test 環境といった環境名は、おそらくはあまり聞き慣れないものではないかと思う。
sandbox 環境
sandbox 環境とは、各インフラ開発者が手動での動作確認やテストコードの実行を行うための専用環境となる。
このような専用の開発環境を設ける理由としては、インフラのテストコードの実行はプロジェクトが復旧不可能な状況に陥る可能性が十分にありえるためである。
具体的な例として、まず Terraform Test の能力を最大限に発揮するためには実インフラ、つまり GCP プロジェクト上に実際にリソースのプロビジョニング(apply)を行うようなテストを実行することになる。
プロビジョニングが完了したら、作成されたリソースに対してテストコードを順次実行していき、テストが完了したら作成したリソースのクリーンアップ(destroy)を実行といった流れでテストが行われる。
そして sandbox 環境での開発中、テストコードは基本的に HCL ファイルの定義を修正するたびに繰り返し実行されることになる。
しかし Google Cloud の App Engine のような一度リージョンを設定してしまったら二度と変更を行えないリソースだったり、実質恒久的に再作成が不可能となるケースが存在するリソース(VPC ピアリングのコネクションと IP 範囲等)に対して、誤った定義でテストコードを一度でも実行してしまうとプロジェクトレベルでリカバリ不可の状況に陥ることになる。
また自分はこの半年間の検証において二度 sandbox 環境の破壊を経験していて、お粗末な話にはなるが、自分の IAM アカウントやサービスアカウントを HCL ファイルに全て定義した状態で試しに何かをした結果、クリーンアップが行われて誰も GCP プロジェクトにログインできなくなるという事件が発生している。
他にもインフラ環境におけるテストコードの実行では常時様々な問題に遭遇することになる。
ここまで学習コストが高い上にインフラ環境を危険に晒してまでテスト環境を導入する意味があるのかと思うかもしれないが、一度ものに出来さえすればインフラ開発の品質を格段に向上させることが出来ると自分は考えている。
sandbox 環境開発のメリット
sandbox 環境の GCP プロジェクトをコマンド一つで再構築出来るようにするシェルスクリプト等さえ事前に用意しておけば、万が一の状況が発生したとしてもすぐにクリーンな環境を再構築出来るようになるため、上記のような問題が発生してもリカバリを直ちに行えるようになり、また Docker コンテナを使用した開発のように sandbox 環境を使い捨て環境のように使用することも出来るようになる。
このように sandbox 環境が破損してもすぐにリカバリできるような状態さえ用意できていれば、staging 環境や本番環境のインフラに変更を適用する前に、クラッシュの可能性がある危険な改修やオペレーションの動作確認なども強気で行うことが出来るようになる。
一方でインフラ開発時に動作確認環境として dev 環境 1 つしか無い場合、インフラ開発者の間で変更適用時に競合が発生しないように事前に変更内容やタイミングを握り合う必要が都度出てきたり、動作確認を行った際に意図しないクラッシュの発生によって予想外に復旧に時間がかかってしまい、インフラ開発全体が一時停止してしまうといった問題が発生する。
なお障害が起きる原因の最たる理由は開発者のテスト不足が挙げられるが、さらにその原因を掘り下げてみるとそもそも開発環境でテストが気軽に行えるようになっていないことが本質的な理由であると自分は考えている。
テストを実施するのが難しい場合、そこからさらに頑張るのではなくテストをサボってしまうといった選択が取られるケースが多々見受けられることからも、気兼ねなく破壊的な検証も行えるような環境を用意することは非常に重要になってくる。
また sandbox 環境はインフラ開発だけでなくアプリケーション開発者のトレーニング環境としても使用することが出来る。
これもまた障害が起きる大きな原因の 1 つになるが、ある改修作業においてアプリケーションエンジニアがインフラへの改修作業をインフラチームに依頼する際に、あまりインフラのことを理解していないために必須の要件を伝えることができずに、その結果お互いの修正がうまく噛み合わず、場合によっては本番環境でその問題が発覚してしまうといったケースもしばしば見受けられる。
この問題はアプリケーションエンジニアがインフラの検証を気軽に試せる環境が存在しないことも大きな一因として挙げられることから、アプリケーションチームに sandbox 環境を 1 つ割り当てることで、インフラへの理解度の底上げと上記結合バグが発生する可能性を減らすことが出来るようになる。
(ただしインフラの初心者が何をやっても絶対に本体が壊れないようにするための仕組み作りや、権限管理は徹底しなければいけない)
test 環境
sandbox 環境は個人の専用環境であるのに対して、test 環境は CI 専用環境になる。
各自の sandbox 環境で開発とテストが終わったのち、変更の push とプルリクエストの作成を行うと Github Actions 上で CI ワークフローが開始されることになるが、ここでは CI 環境専用の GCP プロジェクト上で Terraform のテストコードが実行される。
つまり test 環境はメンバ間で平行に進んでいる開発を集約するための環境になる。
なお sandbox 環境同様にインフラのテストコードを実行することから、test 環境もプロジェクトの破損リスクがある点は考慮する必要がある。
test 環境を 1 つしか用意していない状態にすると、プロジェクトが破損した場合にすべてのデプロイが出来なくなることから、アクティブ・スタンバイ構成などにしておいた方が良いと個人的には考えている。
CI ワークフローとレビューをパスしたらプルリクエストがマージされ、CD ワークフローによって staging 環境へのプロビジョニングが行われる。
そこでの動作確認も問題なければ本番へのローンチを行うといった流れになる。
テスト
インフラ開発をテスタブルに行うためのプロダクト環境については大方説明したので、ここからはインフラプロジェクト内で実行する様々なテストについて順を追って紹介していきたい。
なおプロジェクト内で実行されるテストに関する図を再掲すると以下になる。
もちろんインフラの専門家の方であればインフラプロジェクトの設計に対しておそらく一家言あるかと思うので、以下で説明するテスト設計を改善する方法があればぜひ教えていただきたい。
IaC Tool / Test
本来であればユニットテスト、インテグレーションテストのような一般的なテスト分類で説明をしたいところだが、インフラのテストコードはアプリとは異なり、使用するテストフレームワークや人それぞれの考え方でそれらの分類がかなり異なってくるような気がしている。
(一応 Terraform を提供する HashiCorp 社が定義する各テストの見解も存在する)
よって Terraform の Test 機能を使用したテストを上記図では “IaC Tool / Test” と表記している。
Terraform Test については先ほど少し触れたが、plan コマンドの出力結果に対してアサーションを実行するものと、実インフラに対してプロビジョニングを行った結果に対してアサーションを行う 2 パターンのテストが存在する。
なお plan コマンドベースのテストは (known after apply) の属性に対してテストを行うことが出来ないため、プロビジョニング後のリソースの各属性の値が意図通りであるかを確認するテストは基本的に apply コマンドベースのテストで行った方が良い。
一方で plan コマンドは実際にプロビジョニングが実行されないこともあり、高速にテストを実行出来るため、自分は variable の入力値に対するブラックボックステスト等で使用している。
ただ結局のところ plan と apply どちらのテストであっても、作成・変更された各リソースの属性値が意図する値かを確認することくらいしか現状出来ないような気がしている。
なお HCL(宣言型言語)で定義したリソースをプロビジョニングした結果の属性値は当たり前に同じになるのだからチェックして意味があるのかと思うかもしれないが、Terraform 自身のバージョンアップや Terraform のプロバイダのバージョンアップを続けていくうちに、バグなどによって属性を指定しているにもかかわらず正しくプロビジョニングに反映されないといった問題が発生するケースは十分にありえる。
以前自分のブログで紹介した事例になるが、Java のアプリケーションで json シリアライズライブラリである jackson のバージョンアップを行なった際に、日付の値がうまく変換されない上、エラーも起きずにただ null になるという問題に遭遇したことがあった。
もし仮にこの問題に気づかずにシリアライズした json を DB に書き込んだ場合、データ消失の問題が発生したことになるが、幸い単純なリグレッションテストを書いてあったことで問題を検知することができた。
他にもリファクタリング作業の際にまったく意図しなかった箇所で問題が起きていることを発見出来たりするのは、動いて当たり前に見える地味なテストをきちんと書いておいたお陰だったりすることがほとんどである。
またテストコードを回しながら HCL の定義を実装していると、たまに動いて当然だと思っていたタイミングで予期せぬエラーが発生して、バグの種が存在することに気づくケースがあることからも、インフラ、アプリ関係なく開発時にテストコードはなるべく書いておいた方が良いと思う。
Compliance Test
Policy as Code(以後 PaC)というキーワードはこのインフラプロジェクトの設計を始めた初期の頃に初めて知った言葉になるが、今では自分が最も興味のある話題の一つである。
PaC ではソースコードやシステムの稼働状態等のデータに対して、「oo は xx でなければならない」といったポリシーをプログラムのコードで記述してそのチェックを行う。
そして PaC を実装するためのプログラム言語の中で最も代表的なのが、Open Policy Agent(以後 OPA)が提供する Rego になる。
Rego はポリシーを記述するのに特化した言語で、コード化されたポリシーは JSON で表現された入力データを受け取って、その入力データがポリシーに従っているかの判定を行ったのち、判定結果を JSON で出力する処理を実行する。
この説明だけだと Rego のコードを見たことがない人は一体どんなものか想像が付かないと思われるため、簡単な例として Google Cloud の Compute Engine で起動しているインスタンスの中に許可されていないマシンタイプを使用しているものがないかテストする方法を紹介する。
(なお実際に動作確認を行うには gcloud コマンドと opa コマンドのインストールが必要になる)
まず入力データとなる Compute Engine のインスタンスリストを JSON ファイルとして出力するコマンドは以下のようになる。
$ cd /tmp/
$ gcloud compute instances list --format=json > instances.json
次に入力データを読み込んで、想定外のマシンタイプで起動されているインスタンスが含まれていないかをチェックする Rego のコードは以下のように記述する。
$ mkdir policy
$ vi policy/machine_type.rego
package main
# 将来予定されているOPAのメジャーバージョンアップに事前オプトインするための定義
import rego.v1
# プロジェクト内で利用可能なマシンタイプ一覧を定義
allowed_machine_types := [
"n1-standard-1",
]
# ポリシーの宣言の1行目には "ポリシー名 contains 最後の行の変数名 if {" と書いておけば大抵のケースで正しいといった感覚で読めばよい
deny_machine_type contains reason if {
# gcloud compute instances listコマンドの実行結果は名前のないJSON配列となる
# よってinput[_]と記述することで、JSON配列内の各インスタンスの状態をあらわすJSON値を1つずつ取り出していく処理が実行される
# つまり手続き型言語の "for instance in instances" のような処理と捉えて良い
instance := input[_]
# 各インスタンスのmachineTypeの値のフォーマットは以下のようになる
# "https://www.googleapis.com/compute/v1/projects/infra-testing-google-sample/zones/us-central1-a/machineTypes/n1-standard-1"
# 上記URLをスラッシュで分割後、配列を反転したのち先頭の要素を取り出すとマシンタイプをあらわす文字列"n1-standard-1"が取得できる
# ここでは代入処理だけで、ポリシー判定を行なっていないので次の処理に進む
machine_type := array.reverse(split(instance.machineType, "/"))[0]
# インスタンスで使用しているマシンタイプが許可リストにある場合はポリシーに従っているためルール違反無しとして処理を終了して、次のインスタンスのマシンタイプのチェックを開始する
# 許可リストにないマシンタイプを使用している場合は、ルール違反疑惑が継続され次の行を実行する
not machine_type in allowed_machine_types
# ルール違反状態が続いて最後の行に到達するとエラー扱いとなり、以下のフォーマットのエラーメッセージが表示される
reason := sprintf("running `%v` instance with disallowed machine type `%v`", [instance.name, machine_type])
}
試しに GCP プロジェクトで n1-standard-1 と t2d-standard-1 のインスタンスを 2 つ起動した状態で以下のコマンドを実行した場合、許可されていないマシンタイプが使用されていることを通知する JSON メッセージが出力される。
$ opa exec --decision=main/deny_machine_type --bundle policy/ instances.json
{
"result": [
{
"path": "instances.json",
"result": [
"running `instance-20240710-155829` instance with disallowed machine type `t2d-standard-1`"
]
}
]
}
プロジェクト内のソースコードや設定ファイルに対してポリシーを適用したい場合、まずチェック対象のソースコードファイルなどを JSON に変換しなければいけないが、その点については OPA のプロダクトである Conftest を使用することで一般的なフォーマットのファイルの大半を自動的に JSON に変換することが出来るため、ポリシーの実装者は Rego のコードでポリシーを記述することだけに集中することが出来る。
(変換可能なフォーマットの一覧は公式ドキュメントのこちらのページの中段あたりを参照)
また Conftest を使用することで組織のポリシーをあらわすコードを 1 つのリポジトリに集約して、各ソースコードプロジェクト側では組織のポリシーのダウンロードを行うコマンドとコンプライアンステストを実行するコマンドの 2 つを実行するだけで、コンプライアンステストを CI で実行するような構成にすることも可能となる。
そして組織のポリシーを集約するリポジトリはコンプライアンステストの実行以外にも、開発者たちが持つミドルウェアやインフラの設定に関する"動くナリッジ"を集積する場所としても活用出来ることを踏まえると資産価値はかなり高い。
(組織のポリシーを集約するプロジェクトの実装サンプルにもし興味があれば、こちらを確認していただきたい)
なお OPA はシステムの世界に留まらず、状態を JSON で表現することさえ出来れば世の中のあらゆる事象に対してポリシーに従っているかの判定を行うことも可能であるため、答えに曖昧さが存在しない規則を文章でなく完全にコードで表現することが出来る可能性もゼロではない点に自分は大きなロマンを感じている。
Security Test
仮想通貨は根こそぎ奪われて、機密データはドラマの世界の手際でクラッカーの手に渡り、某クラウドは顧客の GCP プロジェクトを勝手に消しくさるといったように、もはや何一つ信用してはならない時代の到来である。
セキュリティはプロダクトを構築、運用していくために必要な作業の中でも比較的軽視されがちな印象を受けるが、けしてコストや労力を惜しんではいけない非常に高度な専門性が要求される領域であると個人的には考えている。
なおセキュリティの専門家ではなくとも、自身のプロジェクトに対しては出来る限りのセキュリティ対策を施しておきたいところであるが、手軽に導入可能なセキュリティツールとして自分は Trivy を推したい。
Trivy ではインフラプロジェクトを構成する設定ファイルに脆弱性のある設定が含まれていたり、クレデンシャル情報が平文で混入していないかのチェックを簡単に実施することが出来る。
Trivy 用の設定ファイルの定義などの詳細についてはここでは説明を省略するが、trivy コマンドをインストールしたのち、インフラプロジェクトのルートディレクトリ上で以下のような 1 行のコマンドを実行するだけで多くのセキュリティに関するテストを実行してくれる。
# --scanners ...オプションは脆弱性チェック、クレデンシャル情報の混入、セキュリティ上問題のある設定が含まれていないことをチェックするという意味
# --exit-code=1は1つでもテストに引っかかった場合にCIなどをエラー終了させるための設定
$ trivy fs --scanners vuln,secret,misconfig --exit-code=1 ./
脆弱性関連のスキャン以外にも使用 OSS のライセンスに問題があるものが含まれていないかのチェックや、(自分は使い所が全く分からないが)SBOM の出力にも Trivy は役に立つ。
Trivy は導入が非常に容易であるにもかかわらずサポートしてくれる範囲がかなり広いため、インフラプロジェクトに限らずアプリプロジェクトなどでも積極的に導入することをおすすめしたい。
なおセキュリティテストは狭義のコンプライアンステストとも捉えられるため、Trivy がカバーしていないセキュリティに関するテストを OPA や Conftest を使用して自前で実装するといった運用方法になるかと思う。
e2e(end-to-end) Test
最後に現時点で自分のプロジェクトではまだ未実装ではあるが、e2e テストの設計について触れておきたい。
e2e テストとはインフラだけでなくフロント、サーバサイドアプリケーションのテスト等でも出てくるキーワードだが、基本的にはプロダクトのユーザ目線で正しく動作しているかを確認するテストのことを指すのが一般的な定義であるかと思う。
Terraform のビルトインの機能で e2e テストを実行する場合、check ブロックを使用してサーバが正常なレスポンスを返却するかを定期的に確認する方法があるものの、HCL の機能だけでは複雑な要件のテストを実装することは不可能であるため、基本的には手続き型言語(おそらくは Go、必要に応じて TypeScript)でテストを書くことになるかと思う。
なお個人的にはインフラの e2e テストの意味を拡大解釈して、ユーザ面からの画面操作をシミュレーションするテスト(フロント e2e)や、REST API のレスポンスや DB の更新状態の検証(サーバサイド e2e)、負荷テスト等といったあらゆるテストを手続き型言語で実装して、sandbox 環境でアドホックに実行出来るような仕組みを構築するべきだと考えている。
なおこのようなテストはインフラのプロビジョニング、アプリケーションのデプロイ、テストの実行までに時間がかかり過ぎるため、CI に含めることが出来ない可能性が高い。
また sandbox 環境のデータを出来る限り本番環境のものに近づけなければ質の高いテストを実施出来ないことから、アーキテクチャ次第では実行可能なテストがかなり制限されてしまう可能性があるため、その点はアーキテクトやテスト設計者の腕の見せ所になりそうではある。
おわり
以上がテスタブルなインフラプロジェクトの設計についての紹介となる。
なお現時点でこのインフラプロジェクトは現場での実運用に耐えられるかの検証がまだ行われていないためプロトタイプ版という体をとっているが、残念ながら現場で試す機会をなかなか作れないために永遠のプロトタイプ版にまっしぐらの状態である。
もちろん自分としても引き続き導入チャンスを狙っていくつもりだが、この設計を本格的に試してくれる奇特な人、チームがもし存在するならば、ブログや X 経由で連絡をいただければ少々の宣伝と導入への協力に対する努力は惜しまない次第である。