ペアーズのバッチ実行基盤の品質を定義して改善を続けている話
はじめに
こんにちは。恋活・婚活マッチングアプリ「Pairs(ペアーズ)」 SREチームのマネージャーを務めております@marnie0301です。 SREチームは、国内最大級のマッチングアプリ「ペアーズ」の各種インフラ、ミドルウェア、ソフトウェアのコードの運用・チューニングを通してパフォーマンス・信頼性を改善し、開発プラットフォームの構築をする事で開発効率の改善・維持を行なうだけでなく、AI/分析チームといったデータ利用者が利用するデータ基盤の構築・運用にも責務を持つ、まさにサービスの稼働と開発を支える心臓部のようなチームです。
今回書いた事
今回の記事では、300を越える種類で動作しているペアーズのバッチの実行基盤がどのように構成されていて、 どのようにモニタリングや品質定義の運用を行っているかについて紹介できればと思います。
ペアーズのバッチ実行基盤のアーキテクチャ
構成図
はじめにバッチ基盤の構成を簡単に図で示します。
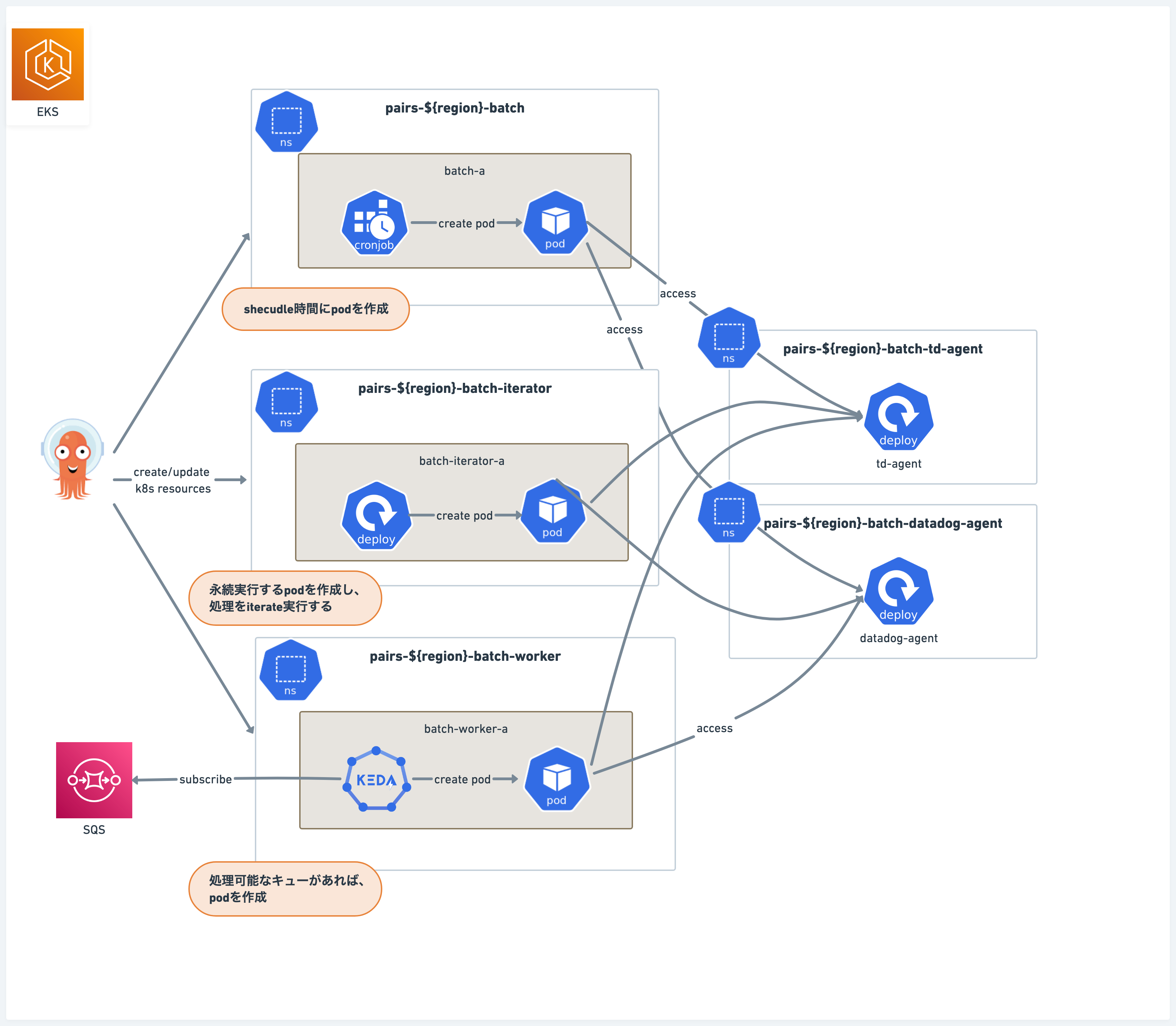
ペアーズの実行基盤はEKS上に構築されており、バッチ基盤もEKSの中の一つのNodeGroup上で動作しています。
バッチの動作タイミング別の種別
ペアーズのバックエンド処理を行うバッチは3種類に分けられます。
-
scheduled batch
- 時刻ベースで起動するバッチ
- CronJobリソースとして定義
-
iterator batch
- 常にループして処理をし続けるバッチ
- Deploymentリソースとして定義
-
worker batch
- SQSなどのキューイングをトリガーに稼働するバッチ
- queueベースでの起動・スケーラビリティの実現にKEDAを利用。
それぞれ用途やスケーラビリティに応じて使い分けられていますが、基本的には強い完全性や一貫性を求められる 処理ではない場合は、スケーラビリティと再実行性が取りやすいようにキューを用いたworker型のバッチの実装を社内では推奨しています。
排他制御と実行数の調整
バッチ処理でよく求められる排他実行やスケーラブルな実行数の実現については、 KubernetesのconcurrencyPolicyやEvent DrivenなAutoScale機能を提供するKEDAを利用しています。
この辺については、より詳細な記事として技術ブログ でも紹介しておりますので、興味がある方はぜひこちらも一読ください。
Tips CUE言語の採用
また、開発者がより簡単にバッチタスクを登録できるように、CUE言語を利用してkubernetesのymlを生成する方式をとっています。 CUE言語を利用する事によって、デフォルトの値や煩雑な設定部分を共通化する事などができますので、開発者側からも評判が良いです。 こちらも詳細は技術ブログに記事がありますので ここでは紹介に留めます。
バッチ基盤の品質を高める
ざっとバッチ基盤の構成について説明をしたところで、 本項から、バッチ基盤をどのように運用していく事で品質の向上を行なっていったかを紹介したいと思います。
品質の定義がないところからのスタート
ここまでに紹介したバッチ基盤はEC2で昔から動作してきたものでしたが、移行に際して苦労したのは、技術的な問題ではなく 運用の問題でした。バッチ処理の品質は移行時点まで未定義のままで、エラーログ数の監視という原始的なアプローチだけで 戦ってきていたので、移行したバッチの動作確認をする際の期待値も曖昧でしたし、アラートの構築などをする事が難しいという 課題がありました。
品質が未定義なままでは、計測するメトリクスも定まりませんし、改善していく方向性や評価も難しく、 アラートやモニタリングなどの精度も弱くなってしまいます。
バッチ処理の品質と運用に必要な情報を考える
そこでまず私たち(SREチーム)は、開発チームと協業でバッチ処理に求められる品質(期待値)やモニタリングするべき情報を以下のように 項目として抽出して言語化する事を始めました。
- 正しく処理は完了したのか
- 処理は期待する時間内に完了したのか (オンラインサービスにおける応答速度に該当)
- リソース不足は起きているのか?リソースが過多すぎないか?
詳細には 次にアラートや運用に必要な情報を定義しました。
定義した品質をメトリクスで表現する
前項で言語化した期待値とメトリクスについて、以下のようなマッピングを行いました。
| 期待値 | 表現するメトリクス |
|---|---|
| 重要度(Severity) | 失敗したらサービスに大きな影響があるなどを包括的に表す |
| 正しくバッチの処理が成功したこと | バッチの終了コード |
| 期待される許容処理時間 | traceから取得された開始〜終了時の計測時間 |
| リソース不足の有無 | kubernetesのcpu/memのusage/request,OOM Killが起きているか等 |
移行時点では終了コードの扱い方がバッチによりバラバラだったので、これらを一つ一つ直して 実装方針を固めたりするという泥臭い所からのスタートだったのはいい思い出です。
メタデータの活用
そしてkubernetes上のresourceとして定義する際に以下のようなメタデータを付与しました。
| 項目 | 内容 |
|---|---|
| description | 処理の概要 |
| owner_team | 当該処理についてレスポンシビリティを持つチーム |
| feature_name | このバッチがどの機能に必要なものか |
| max_consecutive_failures | 連続で何回失敗したらアラートを発火するか |
| manual_retry_required | 失敗時に手動で再実行するべきかどうか。将来的には失敗時に実施するべきRunBookを入れたい |
これらはより実情に即したアラートの発火条件としての利用や、アラート本文に対応ドキュメントを載せるなどに用いられる事で 開発者/SREのアクションを容易にしています。 また、一つの機能を実現するために複数のバッチ処理がセットになっているケースなどがわかりづらいので機能名なども 付与することで関連機能をわかりやすくするなどの利用をしています。
バッチの実装についてのポリシー
バッチの実装はオンラインサービスとは異なる注意が必要で、特にそれらは処理する対象やデータが増えれば増えるほど顕著になってくると 考えており、開発者と相談し、レビュー観点として以下のような項目を検討しています。
再実行の容易性
処理が途中で失敗する事はどんな処理でも必ず起きうるので、処理が失敗した際に簡単に再実行できるようになっているか。
(例) 配信用のバッチが途中で失敗した場合、再実行すると失敗した処理までの処理が重複してしまい二重配信になってしまう → NG
処理量が増えた際のスケーラビリティが担保されているか
具体的な例としては、大きなデータを読み込むことでOOM Killになってしまうような作りになっていないか、や処理する人数が多いので期待される 時間までに終わらず処理が遅延するケースなどです。このようなケースへの対策に対して垂直スケールにも限界があるので一回に読み取るデータを減らす そもそも水平スケール可能な設計を適用できないか、などをディスカッションしています。
失敗時に取るべきオペレーションについて
処理自体をリトライ処理などを取り入れて堅牢に作ったとしてもジョブの失敗は起きる事を前提に考えるべきであり、アラートが鳴った際の深刻度や取るべき オペレーションは事前に定義されているべき項目としてメタデータに記載する事を促します。
その他にも項目として検討しているものはありますが、スタート地点としては上記の項目をベースに検討してます。 今後、継続的に定義と評価を繰り返して、開発者ガイドラインとして整備していこうと考えています。
まとめ
今回はバックエンド処理を支える縁の下の力持ちであるバッチ処理の品質とどのように向き合ってきたかについて紹介させていただきました。 バッチ処理基盤の移行や改善についてはイベントでの登壇資料などでより詳細に記載していますので、ぜひ興味があればご覧ください。 バッチ処理は簡単なようで、オンライン処理と異なる注意点が必要なので、この記事が何かの参考になれば幸いです。