Embedded SREの実践: 開発チームから始めるSRE推進
はじめに
シンプルフォーム株式会社で SRE をしている守屋(@Zepprix)と申します。 当社は設立から 4 年目を迎えたスタートアップで、主に金融機関向けに国内全法人の情報をリアルタイムで提供するソリューションを提供しています。私は一人目の SRE として今年入社してプロダクトの信頼性向上に取り組んでいます。本記事では、Embedded SRE として開発チームの中から SRE を推進している当社での事例をご紹介します。
SREをインストールするターゲット
SRE の実践方法は運用しているプロダクトの特性によって異なります。よって実践の話に入る前に前提条件となる当社の状況についてご説明します。
プロダクトについて
当社は、国内の中小・新興法人も含めた約500万の法人情報を収集し、主に金融機関が法人口座開設時などに行う調査業務に役立てていただくソリューションを提供しています。主力サービスである「SimpleCheck 」は、調査したい法人名を入力すると、Web クローラーが当該法人の最新情報を収集し、さらに当社が独自に収集した様々なリスク情報データベースと突合してレポートとして提供します。また、対象法人を常時監視し、リスク評価に関わる重要な情報や属性に変化が生じた際に通知を行う「SimpleMonitor」というサービスも運用しています。それぞれに詳細については以下の弊社の HP をご覧ください。
技術スタック
プロダクトで利用する主な技術スタックは以下の通りです。
- コンピューティング
- AWS Fargate
- AWS Lambda
- データベース
- Amazon Aurora MySQL
- Amazon Neptune
- Amazon OpenSearch Service
- Webアプリケーション
- Ruby on Rails
- Vue.js
- データ収集/分析
- Python
- Playwright
プロダクトの特性
SRE 的に注目したいプロダクトの特性としては「金融機関等の業務フローに組み込まれている」という点が挙げられます。これにより、以下のような要件に応える必要があります。
- 高い可用性の維持: サービスが停止すると顧客の審査業務に影響が出る
- データの信頼性担保: 誤ったリスク評価につながらないよう、データの信頼性が非常に重要
- 厳格なセキュリティ要件の遵守: 金融機関等の厳しいセキュリティ要件を満たす必要がある
まず何をやるか
当社にはプロダクトの開発チームに加えてインフラチームが設置されています。私もインフラチームに所属し、SRE 活動を始めることになりました。インフラチームは、全プロダクトを横断して AWS インフラの保守やデータ分析基盤の運用を担当しています。まずはインフラ周りの作業を行いながら、SRE をどう推進していくか検討することになりました。
手始めに「SREとは何か」というドキュメントを作成し、その中で一般的な SRE 活動の例と当社の現状を比較した表を作成しました。以下はその一部です。
| 活動内容 | シンプルフォーム社での現状 |
|---|---|
| モニタリング・オブザーバビリティ | CloudWatch、Sentry、New Relic でメトリクスの監視やアラートを実装済 |
| サービスレベル管理 | 各種メトリクス(SLI)を毎日開発チームがウォッチ、SLO やエラーバジェットは未実装 |
| パフォーマンス改善 | スロークエリが散見され、RDS のメトリクスアラートが頻発している |
| ポストモーテム | 週次ミーティングで、障害の振り返りや再発防止策をエンジニア全体で議論 |
| コスト最適化 | AWS 等のクラウドコストが想定より高く、削減計画を進行中 |
| ライフサイクル管理 | 各種ミドルウェアの EOL が近接 |
| 構成管理 | Terraform(Terragrunt)で IaC が整備済 |
| セキュリティ | セキュリティチームが発足し、複数の改善施策を進行中 |
| トイル撲滅 | 多数の課題があるが、機能開発優先のため後回しの傾向 |
この表を用いて、CTO や EM と協議し、当社の課題を洗い出した上で SRE 活動の方針を調整しました。方針について合意が得られ、インフラチームの一員として、可能な部分から改善を進めていくことになりました。
Embedded SREへの転向
主にインフラ方面から改善施策を模索していた中、ある日 EM から次のような提案を受けました。
「しばらく開発チームに移って、機能開発にフルコミットしてもらえないか?」
実はインフラチームに入った当初から、プロダクトのアーキテクチャ理解の一環として簡単な開発タスクを時々担当していました。加えて当時、Ruby on Rails の開発経験があるエンジニアが不足しており、以前の職場で開発経験のあった私に白羽の矢が立ったのです。これは SRE を推進していく上でチャンスだと考えました。
SRE が開発チーム内に配置される体制を「Embedded SRE(組み込みSRE)」と呼んだりします。EM から開発への参加を提案された際、せっかくなのでこの体制から SRE 活動をスタートしてみようと決意しました。当社では開発にスクラムを採用しており、週初めのスプリントプランニングから週末のスプリントレビューまで、一連のスクラムイベントを実施しています。私も開発チームの一員として全てのイベントに参加し、機能開発に携わることになりました。正直、当初は開発に精一杯で SRE 活動どころではなかったのですが、実際にコードを書く中でプロダクトの内部構造を把握できたのは大収穫でした。しばらくして開発に慣れてきた頃から、徐々に SRE 活動を取り入れていきました。
スプリントに少しずつSRE活動を組み込む
開発チームのバックログには、機能開発だけではなく、時間があれば取り組みたい運用改善系のタスクも多く積まれています。機能開発を優先せざるを得ない状況ではありますが、スプリントごとに少しずつ改善が進むよう、スプリントプランニング時にそういったタスクを少しずつ組み込むようにしました。
スプリントレビューでSRE活動を報告
スプリントの終盤には、各開発チームの一週間の成果物を社内に共有するスプリントレビューが行われます。私が所属する開発チームの発表に「今週のSRE活動」を追加し、進捗や成果を共有するようにしました。これには、エンジニア以外のプロダクトマネージャーやビジネスメンバーにも SRE への認知を広める狙いもありました。以下はミーティングで共有を行った際の議事録ですが、幸いにも好意的なフィードバックをいただくことができました。
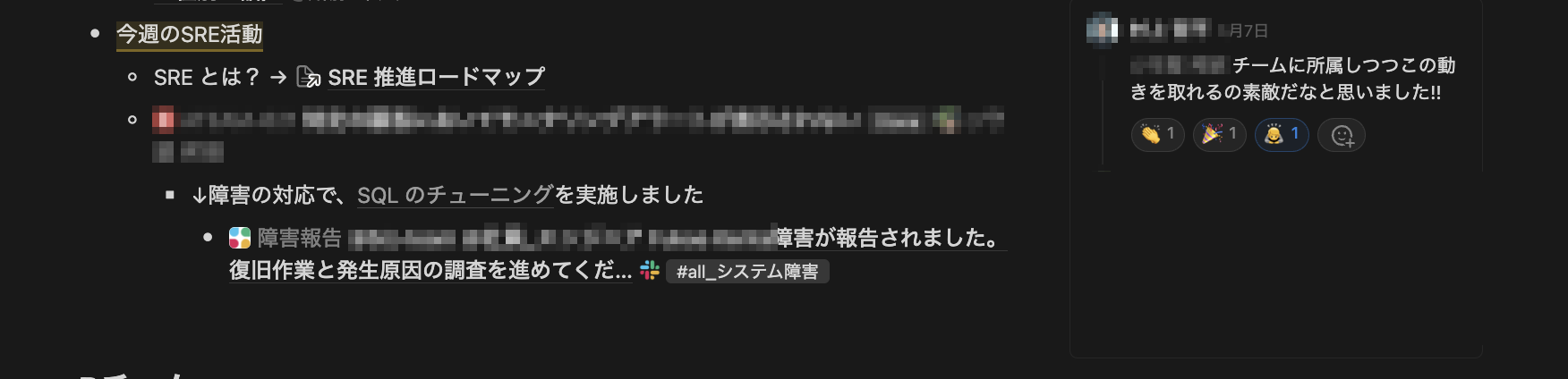
具体的なSRE活動の例
開発チームで取り組んできた直近の SRE 活動の一部をご紹介します。
パフォーマンス改善
前述の表にも記載したように、スロークエリが散見され、RDSの CPU やメモリ使用率が頻繁にスパイクして可用性を脅かす状況でした。改善策としてチームで以下のような取り組みを実施しました。
- スロークエリの Slack 通知による可視化
- インデックスの見直し
- クエリのチューニング
- Redis キャッシュの導入
以下は実際のスロークエリの Slack 通知の例です。
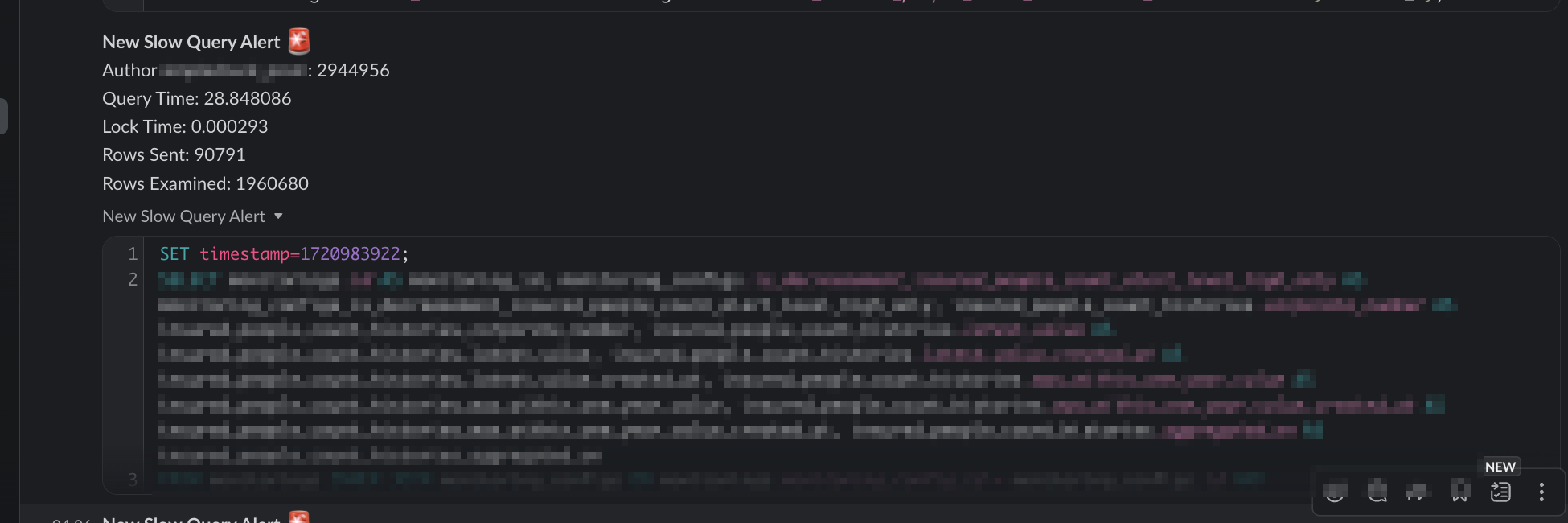
こちらの Slack 通知については以下の記事を参考にさせていただきました!
また、メモリスパイクの問題に対処した際の知見を別途記事にまとめていますので、ご興味あればご覧ください。
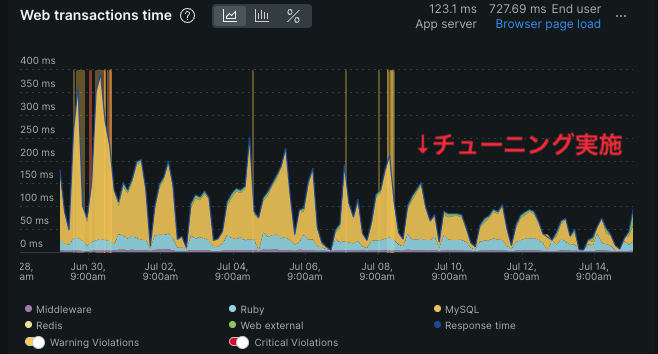
チューニング実施後、New Relic APM で可視化したレスポンスタイムの推移から、MySQL の負荷が低下していることが確認できました。
ライフサイクル管理
プロダクトで利用している各種ミドルウェアの EOL が近いため、チームでアップデートに取り組んでいます。対象は以下の通りです。
- Ruby
- Node.js
- Python
- Aurora MySQL
特に Aurora MySQL は、 v2(MySQL5.7相当) から v3(MySQL8.0相当)へのメジャーバージョンアップとなり、クエリキャッシュの廃止によるパフォーマンスの悪化が懸念されました。そこで負荷試験を実施してアプリケーション全体の処理性能への影響を検証しました。結果として同時接続数を上げていくにつれて v2 よりもやや早めに CPU が限界に達することが判明しましたが、諸々のチューニングや Redis キャッシュの導入により、アップグレード後も問題なく高負荷を処理できることを確認しました。 その他のミドルウェアについてもチームの尽力もあり一通り対応が完了しましたが、SRE 観点では、ライブラリも含めて継続的にバージョンアップしていく体制作りを目指しています。
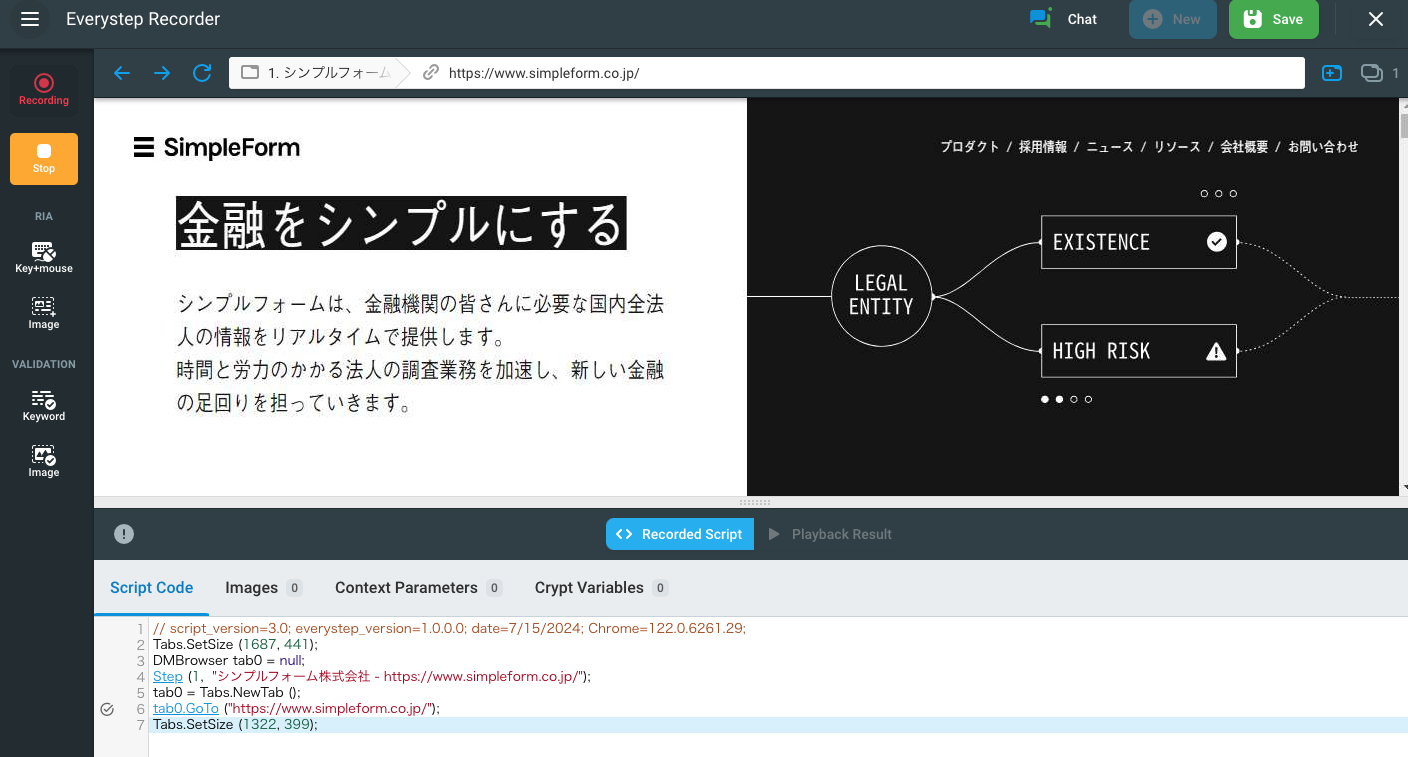
負荷試験には「loadview」を使用し、ユーザーのブラウザ上での動きを再現したシナリオを作成しました。Web レコーダーを使用して実際に試験対象のページを操作しながらシナリオを作成し、入力フォームの値は CSV でパラメータ化しました。正直お値段は少々高めではありますが、使い勝手は非常に良好でした。
Embeddedされてよかったこと
プロダクトの内部構造を深く理解できる
SRE 推進役がインフラからアプリケーションまで一気通貫で把握していることで以下のような恩恵が得られました。
- 開発メンバーと同じ目線で信頼性向上施策について議論ができる
- 障害発生時の原因切り分けを自身で対応できる
- 信頼性における課題の洗い出しをより深いレイヤーから行える
エンジニア以外のメンバーとの連携機会が増加
開発タスクを担当することで、自然とプロダクトマネージャーやビジネスメンバーとのコミュニケーションが増加しました。今後、SLO やエラーバジェットを本格的に運用していく上で、エンジニア以外のステークホルダーとの信頼関係は必要不可欠です。この連携の増加は、SRE を全社的に広めていく土壌を作る上でも非常に有意義だったと感じています。また、今後も連携を強めることで、エンジニアリングだけではなくビジネスの観点も含めて信頼性を定義していくことも可能になるのではないかと考えています。
まとめ
Embedded SRE として開発チームの中から SRE 推進を行っている当社での事例をご紹介しました。自身も開発に携わることでプロダクトの内部構造を理解した上で SRE 活動を行えることは大きなメリットだと感じています。今後は他の開発チームにも SRE をインストールしたり、QA チームと連携してデータの信頼性を高めるための施策やセキュリティチームとの連携も模索していきたいと考えています。本記事が皆様の組織で SRE 推進を行う上で少しでも参考になれば幸いです。