データ分析基盤の運用にSREのプラクティスを取り入れる
はじめに
こんにちは。恋活・婚活マッチングアプリ「Pairs(ペアーズ)」 を運営する株式会社エウレカ SRE/Data Platform チームの@hisamouna34です。 私たちはインフラやソフトウェアの運用・チューニングを通じて、パフォーマンスや信頼性の改善に取り組んでいます。また、開発効率を支えるプラットフォームの構築や、データ分析基盤の運用も担当しています。 データ分析基盤の運用・改善にも日々取り組んでいます。 この記事では、私たちがデータ分析基盤の運用に SRE のプラクティスをどのように適用しているかを紹介します。SRE チームやデータエンジニアリングチームがデータ分析基盤を運用する会社の参考になれば幸いです。
ペアーズのデータ分析基盤アーキテクチャ
構成図
以下は、ソースデータから分析基盤で利用可能になるまでの簡略化した流れを示した構成図です。
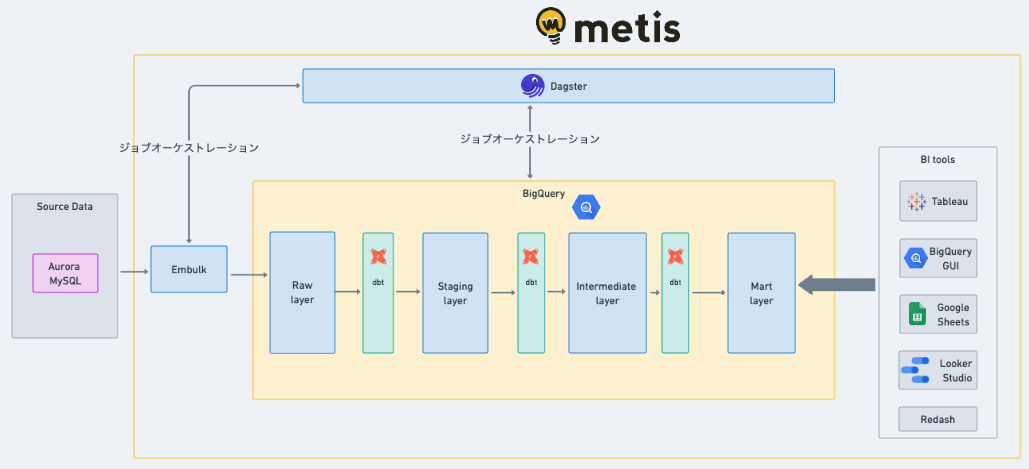
技術スタック
- データソース: Aurora MySQL (図には表現していないですが、DynamoDB, S3 などもあります)
- データオーケストレーション: Dagster on GCE
- データの取り込みや加工を実行するジョブの管理
- データウェアハウス: BigQuery
- データを分析しやすい形に加工し、保管
- データローダー: Embulk on ECS on Fargate
- データソースから取得し、データウェアハウスにロードする役割
データレイヤリング
Raw layer: データソースをそのまま取り込む層
Staging Layer: Masking 処理など分析前処理を施した層
Intermediate Layer: 特定の分析用途のために加工を施した層。ロジックのSSoTとなる
Mart Layer: BIツールなどのダッシュボードと1対1で使用するように加工された層
BigQueryのデータ更新ジョブ
現在、レイヤごとに更新ジョブを3つの粒度に分けています。
① Embulkによる Raw Layer のデータ更新ジョブ
② dbtによる Staging Layer のデータ更新ジョブ
③ dbtによる Intermidiate ~ Mart Layer のデータ更新ジョブ
データ分析基盤に SRE のプラクティスを適用する
システムの期待値を定義し、遵守できているか確認する
SRE の代表的なプラクティスとして SLO (Service Level Objective) があります。SLO はシステムの期待値をステークホルダー間で明確にし、定量的に評価可能にする目標値です。 最初のステップとして SLO の導入とまではいきませんが、Availabity/Latencyの2 つの指標でシステムの正常性を把握するようにしていきました。
Availability
- ジョブの実行が成功したか失敗したか
- Dagster のプロセスが起動しているか
Latency
- ジョブの実行時間
Availability に対する対応
ジョブの失敗や Dagster のプロセス停止が発生した際にアラートを送信する仕組みを導入しました。 重要なのは、アラート時に迅速な原因調査ができるようにすることです。そのために以下の対応を実施しました。
- 関連メトリクスをダッシュボード化
- メトリクスを事前にまとめ、視覚的に確認できるようにする。
- エラーログの永続化
- 調査時に必要な情報を失わないようにログを保存する。
Latency に対する対応
Embulk のジョブ実行時間が事前に定義した目標時間内に収まるか確認しています。 目標時間は、ダウンストリームのレイヤ(Intermidiate ~ Mart Layer)の更新ジョブの期待更新完了時間をまずは決定し、そこから逆算で依存元のアップストリームのレイヤ(Raw, Staging Layer)の更新ジョブの期待更新完了時間を決定していきました。 現状は後述する定期のメトリクス確認時に、直近の状況を確認し目標時間内に実行が完了しているかを確認します。
ここでも重要なのは、異常時に調査可能なようにしておくことです。 例えば、Embulk ECS タスクの CPU/Memory 使用率をメタデータとして実行履歴に残しておくなどです。 ECS の Container Insight では run_task の task ごとのメトリクスを確認できなかったので、ロググループでメトリクスフィルターを設定し、出力されたログイベントから CpuUtilized および CpuReserved を抽出するようにしました。 CPU使用率が高いならスロットリングが原因でデータ更新時間が遅くなってしまっていることが推測できたり、メモリ使用率が100%に近いなら OOM が発生し更新のプロセスが中断してしまった可能性を推測することができます。
定期的なメトリクス確認
GCE や Embulk のメトリクスを週次で確認し、以下のポイントをチェックしています。
- 変化を見る
- 前週比で CPU 使用率が高まっていないか
- データ取り込み量が減少していないか
- ECS タスク数の傾向が変わっていないか
- ジョブ実行時間が長くなっていないか
Runbookの作成
各ジョブがどのデータを管理しているか、そしてジョブ失敗時の対応方法をドキュメント化することで、トリアージが属人化しないようにしています。 アラートのメッセージに Runbook のリンクを添付しておくことで、ドキュメントを探す手間が省け即座に対応を行うことができます。
おわりに
本記事では、ペアーズのデータ分析基盤運用に SRE のプラクティスを適用した事例を紹介しました。
まだまだ十分な Reliability を持つデータ分析基盤を構築できたとはいえず、改善ポイントは以下以外にもたくさんあります。
- ビジネス要件をより反映したデータ品質チェックテストの拡充
- 現状では null や重複データのチェックテストを実施していますが、さらに高い品質基準を目指して改善を進めていきます。
SRE チームがデータ分析基盤の運用を担う企業にとって、これらの手法が参考になれば幸いです。