ペアーズのIncident Botによるインシデントレスポンス支援
はじめに
こんにちは。恋活・婚活マッチングアプリ「Pairs(ペアーズ)」を運営する株式会社エウレカ SRE/Data Platform チームの@goat0613です。ボルダリング部部長も兼任しています。
私たちはインフラやソフトウェアの運用・チューニングを通じて、パフォーマンスや信頼性の改善に取り組んでいます。また、開発効率を支えるプラットフォームの構築や、データ分析基盤の運用も担当しています。
この記事では、ペアーズがインシデントレスポンスの補助として導入しているIncident Botについて紹介します。インシデントレスポンスを効率的に行いたい、コマンダー負荷を改善したい、といった会社の参考になれば幸いです。
インシデントレスポンスにおけるコマンダーの課題
コマンダーの役割
インシデントレスポンスにおいて、コマンダーは対応の中核を担う重要な役割です。
コマンダーの役割は、インシデント対応の全体を統括し、関係者と連携しながら、迅速な復旧へと導くことにあります。
具体的には、以下のようなタスクを担います。
- 障害の影響範囲を特定し、深刻度(Severity)を判断する
- インシデント対応のためのコミュニケーションチャンネルを作成し、関係者を招集する
- 対応状況を整理し、進行管理を行う
- 経営陣やカスタマーサポートなど、技術チーム以外の関係者との橋渡しをする
- インシデント収束後にポストモーテムを実施し、振り返りを行う
コマンダーが抱える課題
コマンダーには、障害発生という非常事態の中で、リアルタイムの意思決定能力、マルチタスク能力、冷静な状況判断力など、通常業務とは異なるスキルが求められます。そのため、精神的・認知的負荷が非常に高くなります。
一方で、大規模なインシデントは頻繁に発生するものではないため、新人コマンダーが経験を積む機会は限られています。 その結果、特定のコマンダーに依存しやすくなり、属人化が進むという課題が生じます。 さらに、習熟度の高いコマンダーが不在の場合、対応の遅れにつながり、TTR(Time to Recover)が増大するリスクがあります。
これらの課題を解決するため、ペアーズでは Incident Bot を開発し、標準化されたインシデントレスポンスフローへコマンダーを誘導し、負荷を軽減する取り組みを進めています。
本記事では、Incident Botがどのようにコマンダーを支援するのか、その設計や実装のポイントについて紹介していきます。
ツールを作る前に必要なこと
インシデント対応の効率化を目指すうえで、ツール導入は手段であり目的ではありません。 まず重要なのは、理想的なインシデントレスポンスフローを定義することです。 これには、ロールの定義、対応フェーズの整理、各フェーズでのアクションの明確化などが含まれます。
例えば、ペアーズでは下図のようなレスポンスフローを設計しています。
(実際のフローよりも簡略化しています)
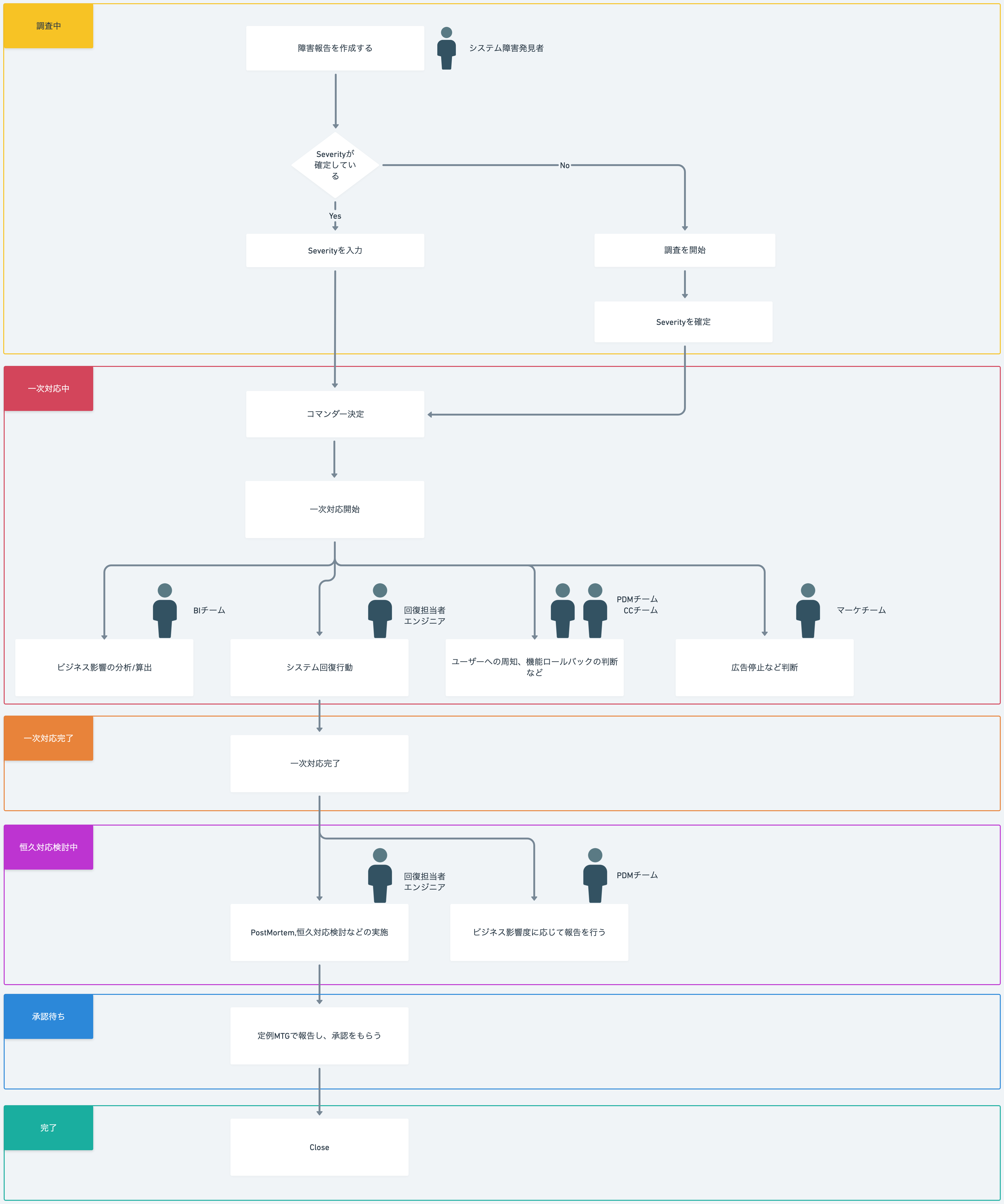
このように、想定するレスポンスフローを明確にし、コマンダーが自然とそのフローに則った対応ができるように、支援ツールを開発することが重要です。
また、サードパーティのインシデントマネジメントツールを使用する選択肢もあります。
この場合も各ツールには、それぞれ想定するインシデントレスポンスフローが存在するため、自社の組織規模や体制と照らし合わせ、運用に適合するかを確認するとよいでしょう。
ツール開発の上で注意すべきこと
ペアーズの Incident Bot は、コマンダーの負荷軽減を目的とした機能を多数用意していますが、中にはコマンダーがアクションしなければならない機能が存在します。例えば「対応フェーズに応じたアクションのリマインド」(詳しくは後述)の機能では、コマンダーが事前に対応状況を入力する必要があります。
こうしたアクションの積み重ねによって、コマンダーの負荷がかえって増大し、ツールが推奨する標準フローから逸脱してしまう恐れがあります。
この機能の例で言えば、「Severityの決定など、他のアクションから自動的に対応状況更新する」ことで、コマンダーの負荷を軽減できる可能性があります。
機能の提供による負荷軽減が、コマンダーに求めるアクションのコストを上回るように設計することが重要です。
ペアーズにおけるbotによるコマンダー負荷の軽減
それではペアーズで実際に行っている、Incident Botによるインシデントレスポンス支援をご紹介します。
アーキテクチャ
多くの機能はSlackからのアクションを起点としており、Slack Bot、API Gateway、Lambda、DynamoDB、JIRAで処理しています。
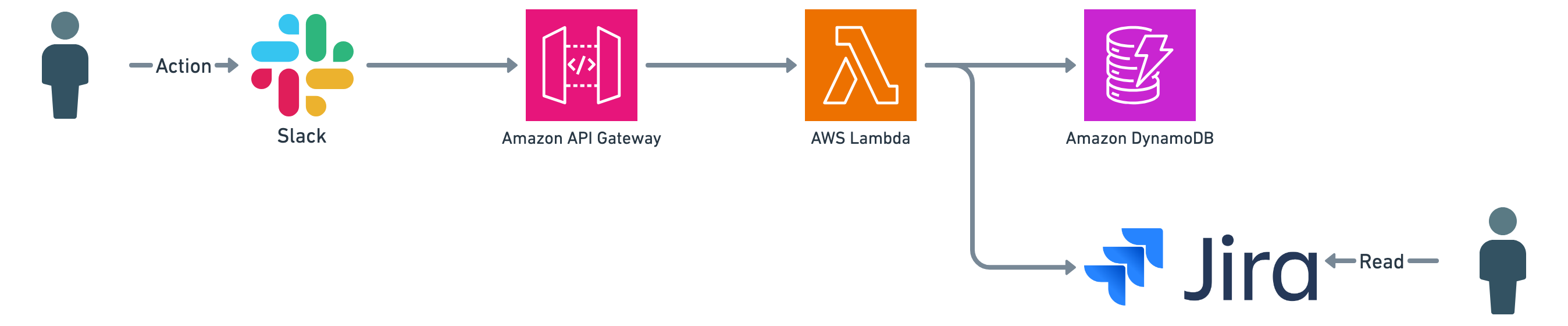
DynamoDB
BotのDBとして使用しています。Slackで入力された情報や、コマンダー・対応Slackチャンネル情報などを保存しています。
また、インシデントレスポンスフロー分析のためにレコードの上書きは行わず、ヒストリカルに保存しています。
RDBのほうがデータは取り回しやすいですが、運用コストを考慮してサーバーレスDBを選択しています。
JIRA
ビューとして使用しています。
インシデントの振り返りなど、障害データを閲覧したいケースは多々あります。管理画面を作成するのはコストに見合わないため、DynamoDB更新と同時にJIRAにもダブルライトを行い、JIRAをビューとして使用しています。
連携情報はインシデントタイトルや概要、障害発生・検知・収束日時などです。
また、ペアーズではポストモーテムドキュメントにConfluenceを使用しており、インシデントJIRAチケットと連携しやすいこともメリットの1つです。
botの支援内容
ここからは主な機能の紹介です。
インシデント対応チャンネルの作成と関係者の招待
Slackコマンドからインシデントのタイトル・Severityを入力すると、botが自動的にインシデント対応用のSlackチャンネルを作成します。
また、Severityに応じたチームメンバーを自動的に招待します。
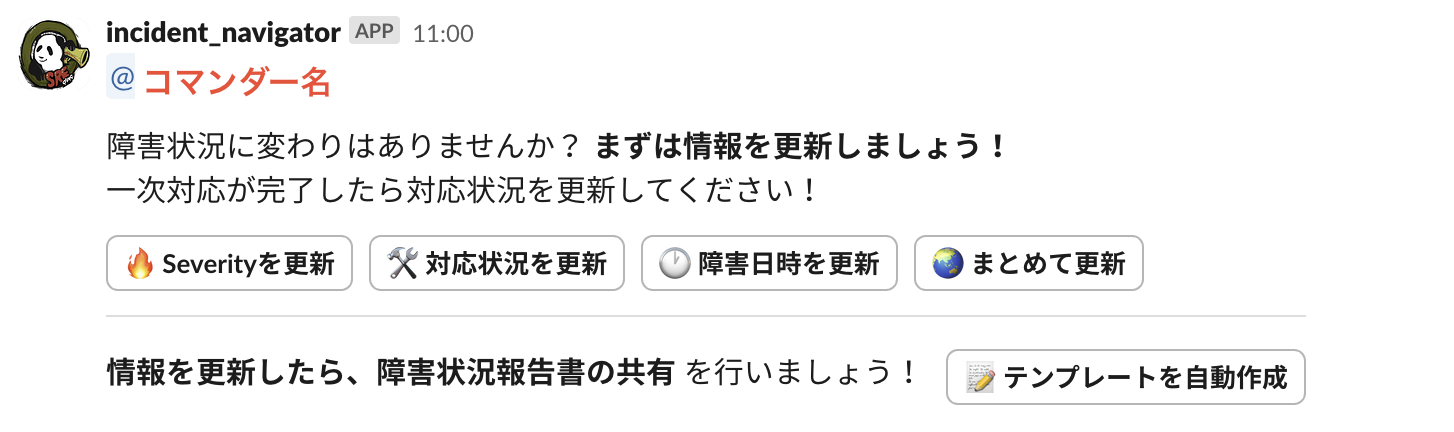
対応フェーズに応じたコマンダーアクションのリマインド
コマンダーが行うべきアクションのリマインドを行います。
コマンダーへの指示が長すぎると読み込む負荷が大きくなるため、対応フェーズごとに必要なアクションだけを記載するよう、メッセージを切り分けています。
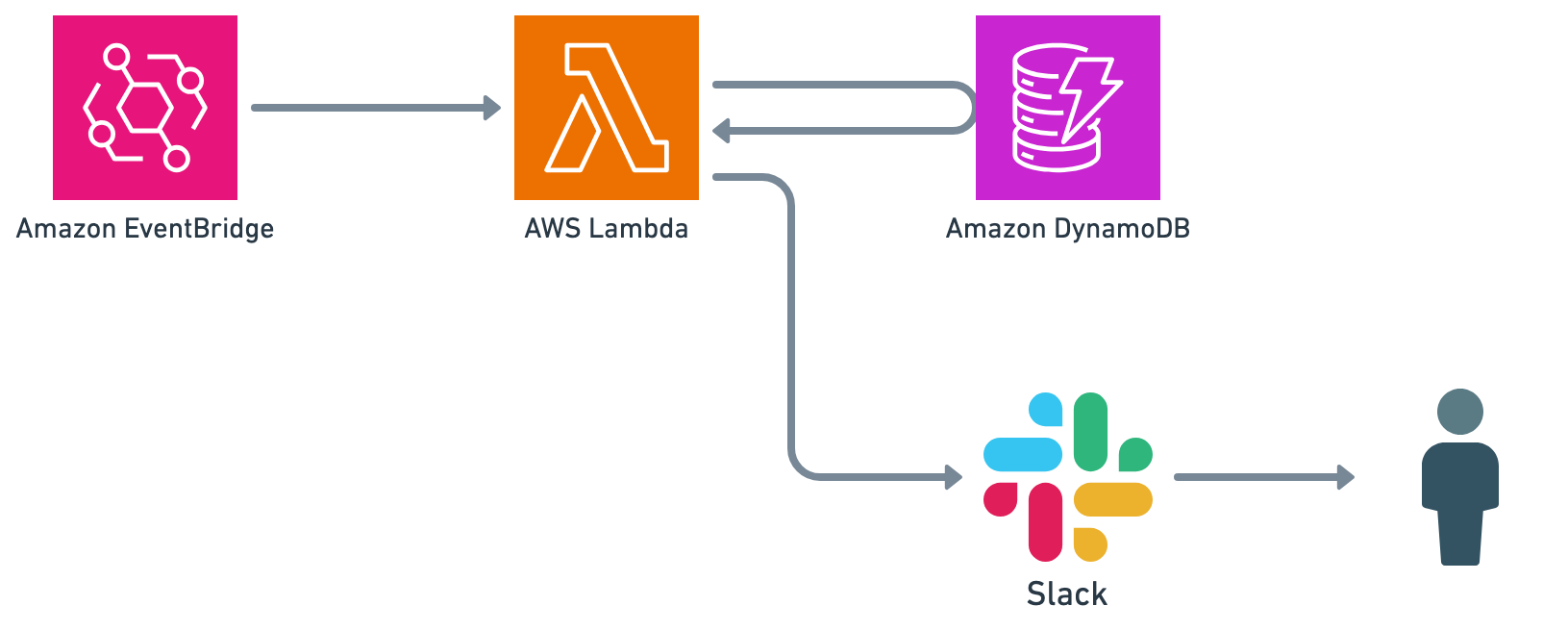
特に一次対応中は、対応状況の変化を関係者に共有する必要があるため、定期的にbotからコマンダーにリマインドを行い、共有を促すようにしています。
リマインダーは、EventBridgeをトリガーに使用しています。
共有必須情報の入力インターフェースの提供
障害情報においてステークホルダーの行動が変わる重要な情報(Severity、障害発生時間、対応状況など)は確実に共有されるべきです。
これらの情報の共有漏れが無いよう、選択式の入力インターフェースを用意しています。
実装当初はすべての情報を入力するモーダルを用意していましたが、「対応フェーズによって更新すべき情報は異なり、必要最小限の情報入力にとどめ、対応に集中したい」というフィードバックを受けました。例えば、「一次対応中は障害発生日時は重要なものの、障害検知・収束日時は重要ではなく、一次対応完了後の入力で良い」といったようなものです。
このようなフィードバックを受け、各フェーズに応じた入力モーダルを用意しました。
(調査中に主に使用されるモーダル)
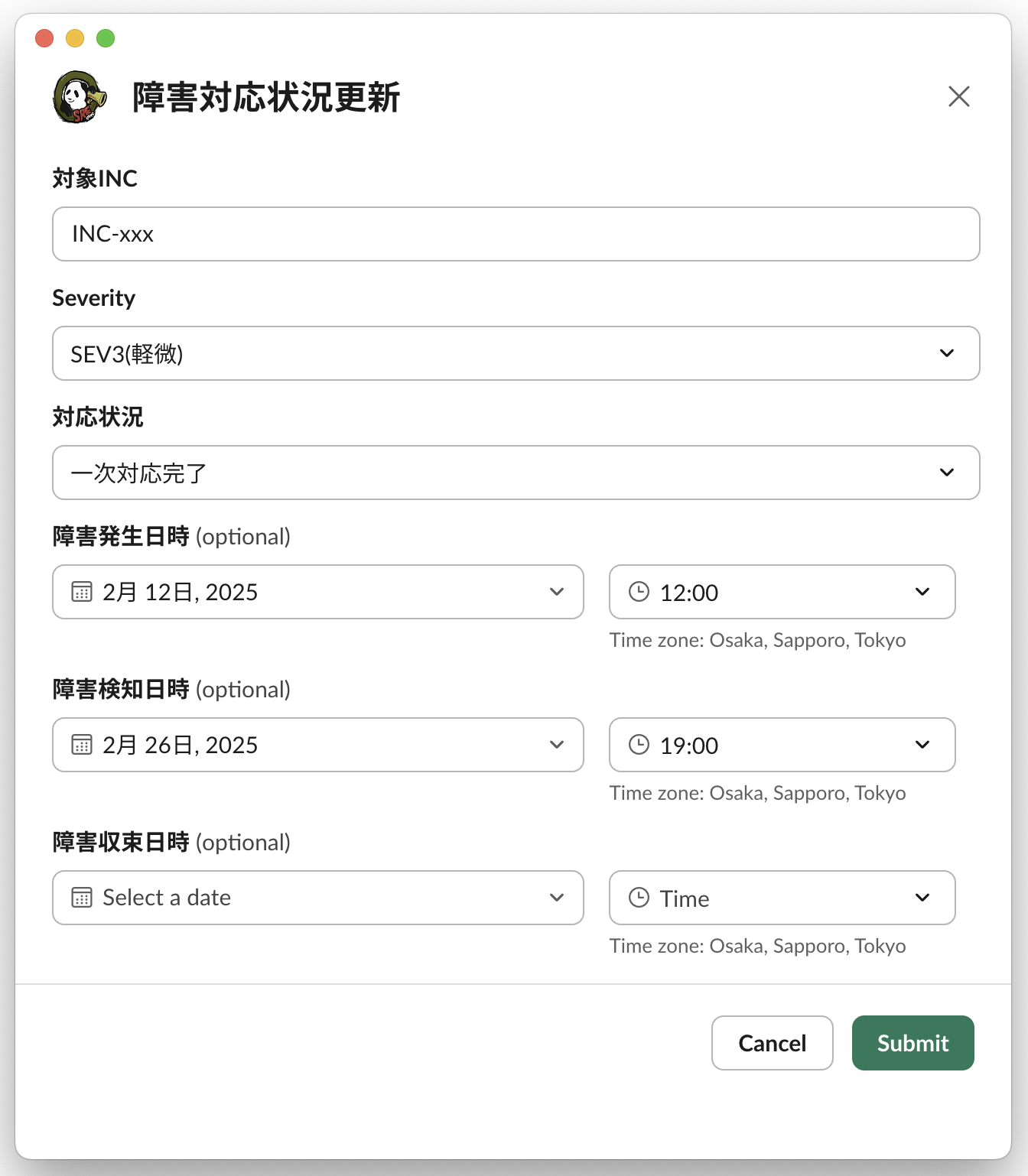
(一次対応完了後に主に使用されるモーダル)
インシデント対応状況報告書の自動生成
ペアーズではインシデント対応状況を報告書の形で関係者に逐次共有しています。
しかしメッセージや会話から報告書をまとめることも負荷が大きいです。
このため、LLMを用いてSlackのメッセージとbotに入力済みの情報から対応状況報告書の草案を作成することで、コマンダーの負荷を軽減しています。
ポストモーテムドキュメントの自動生成
一次対応が完了したら、コマンダーは後日ポストモーテムを開催します。効率的なポストモーテムのため、議論のベースとなる情報をまとめておくことが必要ですが、こちらも対応状況報告書と同様、LLMを用いて草案を自動生成しています。
対応状況報告書、ポストモーテムドキュメントのLLMを用いた自動生成について、詳しくはこちらの記事をご覧ください。
長期的なレスポンスフロー改善のための計測
botで対応状況の変更ログを保持することで、どのフェーズで時間がかかっているかなどの分析を行えるようにしています。
今後はこのデータを、インシデント単体ではなく、インシデントレスポンスフロー自体の改善に活用していきます。
まとめ
本記事では、ペアーズにおける Incident Bot の活用事例をもとに、ツールを活用したインシデントレスポンスの最適化について紹介しました。
元来、インシデントレスポンス、特にコマンダーの負荷は非常に高いものです。 この負荷を下げ、コマンダーの民主化、TTRの削減へのアプローチの1つにツールによる負荷削減が挙げられます。 ツールによる負荷削減では、まず理想のインシデントレスポンスフローを描き、その行動への負荷を下げるようツールを作成することが重要です。
インシデントレスポンスの改善を行いたい組織にとって、ペアーズの事例が参考になれば幸いです。