巻頭言:一人SREの孤独を埋めるNotebookLM
MIXIでSREをやっているしょっさんと申します。
今回の巻頭言は、最近弊社で利用できるようになったNotebookLM Plusを使って、一人SREの孤独を埋めるために活用していく簡単な話をします。
と、その前に宣伝をひとつ。
SRE Kaigi 2025のアーカイブ動画が配信されました!
https://www.youtube.com/@SREKaigi
ぜひとも見逃したセッションがございましたらご視聴ください!🙏
NotebookLMとは?
ご存じない方のために簡単にご説明すると、NotebookLMは、Googleが提供する「自分専用のAIアシスタント」です。 Googleドキュメント・PDFやWeb URL、動画などを読み込ませると、それらのソースをもとに質問に答えてくれて、カスタムされたプロンプトを実行することも可能です。
例えば、プロジェクトの仕様書を読み込ませることで「仕様書について答えてくれるくん」になってくれるわけです。便利ですね〜〜〜。
無料でも使えるのですが、その場合ソースは50個まで、カスタムプロンプトは使えないなどの制限があります。(※ それでも十分使えます☺️)
Plusになると、ソースは300個まで、カスタムプロンプトが利用でき、ノートブックを共有している場合はアクセス分析などができます。
正直、ソースを300個も読ませるのか・・・?と思ったりするかもしれませんが、仕様書だと割と使い切っちゃう数かもですね。
SREについて壁打ちしてくれる存在が欲しい
さて、そんなNotebookLMですが「何に使ったものかな〜〜〜」と考えておりましたが、一人SREのもっぱらの悩みである「壁打ち相手がいない」に使えそうだということでやってみました。
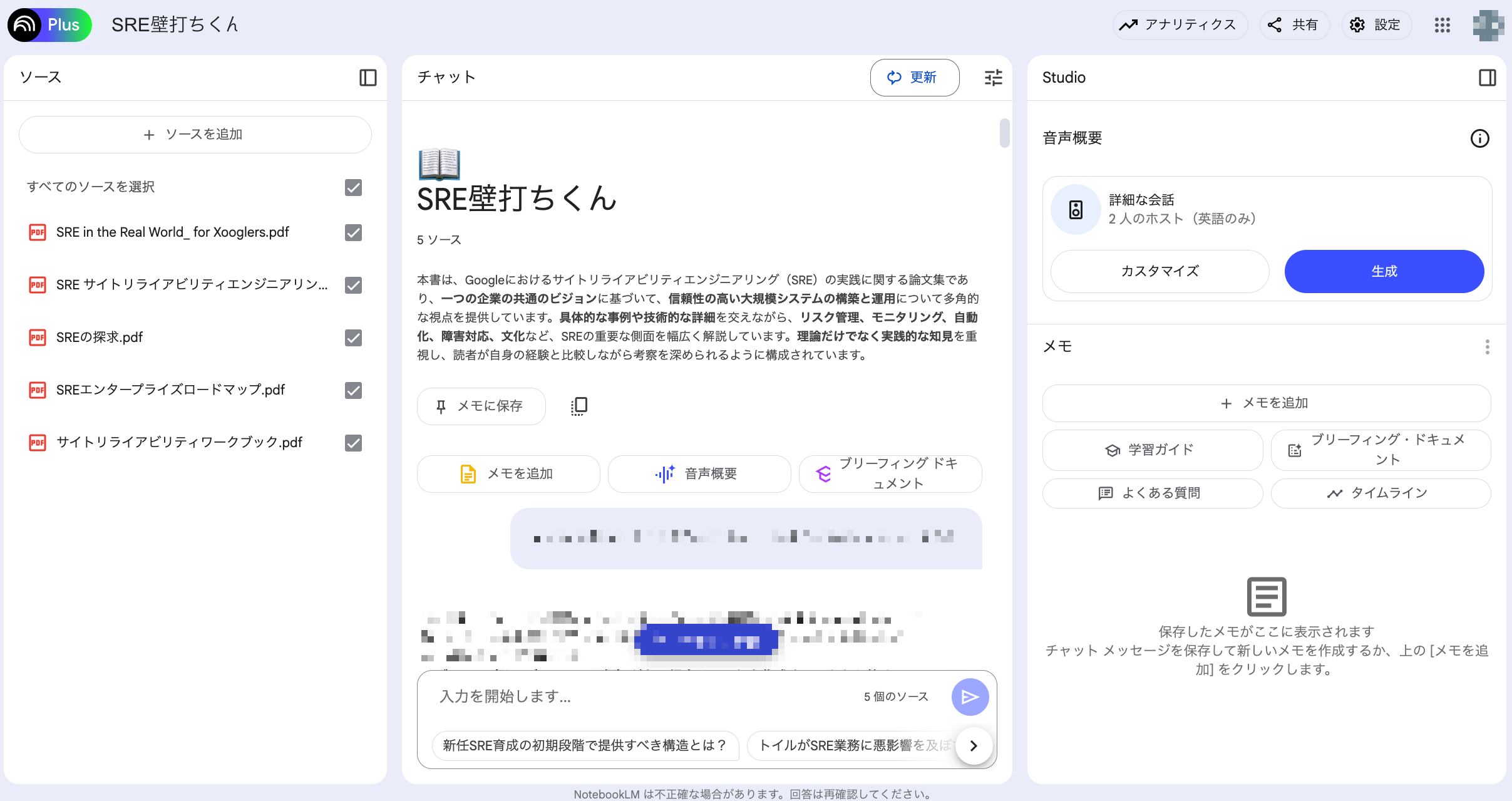
というわけでSRE壁打ちくんを誕生させました。
ソースのところを見たら分かりますが、原典のSRE本をもとに手持ちのSRE関連書籍を読み込ませています。他にもYouTubeやWeb記事などをガンガン読み込ませるのもよいのですが、ソースを読み込ませる量が多くなると、回答精度が悪くなるといった事象がチーム内であったので、一旦必要最低限の数に留めています。
あとはカスタムプロンプトもせっかくなので使ってみております。以下のようなプロンプトですが、特に問題なく返してくれていますね。回答精度が上がっているのかどうかはちと疑問ですが・・・プロンプト作りムズカシイ
私の質問に対しては、読み込んでいるSRE関連書籍を元にした根拠を交えつつ、実践的で再現性の高いをGoogleが提唱するSREの原則と実践に精通したパートナーとしてアドバイスをください。必要に応じて、実例や推奨手順、参考ページも示してください。
また、私の考えや提案に対しては、盲目的に肯定するのではなく、SREの原則に照らして建設的なフィードバックをしてください。
壁打ちしてみよう
それでは、こちらのSRE壁打ちくんを使ってみましょう。今回は想定として「とりあえず可用性をSLIに据えてるけど、もう少しSLI/SLO改善していきたい」といった内容で壁打ちしてみます。
Q. 現在のプロジェクトでは可用性をSLIとしています。ここからSLI/SLOを改善をするにはどのようなアクションが考えられるでしょうか?
A.
現在のプロジェクトで可用性をSLIとされているとのこと、SLI/SLOの改善に向けてどのようなアクションが考えられるかについて、Googleが提唱するSREの原則と実践に基づき、読み込んでいるSRE関連書籍からの根拠を交えながら、実践的で再現性の高いアドバイスをさせていただきます。
現在の可用性をSLIとしている状態から改善を図るには、より詳細な可用性の定義と、他の重要なサービスレベルの側面を捉えるためのSLIの追加を検討することが重要です。
■ 可用性のSLIの改善
現在、可用性をどのような指標で計測されているかによって、改善の方向性は異なります。SREの文脈では、可用性は一般的に「成功したリクエストの割合」として計測されます。もし現在の計測が単なるシステムの起動時間などであれば、ユーザーが実際にサービスを利用できているかをより正確に反映する指標に改善することを推奨します。
具体的な改善策としては、以下のようなものが考えられます。
• SLIの仕様と実装を明確にする: ユーザーにとって重要なサービスの成果を評価する「SLIの仕様」と、それを実際に計測する方法である「SLIの実装」を区別し、それぞれを詳細に定義します。例えば、「ホームページが100ms未満でロードされること」という仕様に対して、「サーバーログのレイテンシ列で計測する」といった実装を定めることができます。
• 計測の視点をユーザーに近づける: 現在サーバーサイドで計測している可用性を、ロードバランサーやクライアントサイドでの計測に切り替えることを検討します。これにより、ユーザーが実際に体験している可用性をより正確に捉えることができます。例えば、合成トラフィック(synthetic traffic)を利用して、定期的にユーザーのクリティカルなパスをテストし、その成功率をSLIとすることも有効です。
• 集計方法と計測頻度を標準化する: SLIの集計インターバル、対象領域、計測頻度、対象となるリクエストなどを標準化し、再利用可能なテンプレートを作成することで、一貫性のあるSLI運用が可能になります。
• より詳細な障害分類に基づく可用性: 単純な成功/失敗だけでなく、HTTPステータスコード(例えば5xxエラーのみを失敗と見なすなど )、エラーの種類などに基づいて可用性を計測することで、より深い洞察を得られます。
■ 他のSLIの検討
可用性だけでなく、サービスの特性やユーザーのニーズに合わせて他のSLIも導入することで、サービス全体の健全性をより包括的に把握できます。一般的なSLIとしては、以下のようなものがあります:
• レイテンシ: リクエストに対する応答時間。平均レイテンシ、パーセンタイル値(例:95パーセンタイル値)などで計測します。
• エラー率: 受信したリクエストに対するエラーの割合。特定のエラータイプに絞って計測することも可能です.
• スループット: 単位時間あたりに処理できるリクエスト数.
• 耐久性: データストレージシステムの場合、長期間にわたってデータが保持される確率。
どのSLIを選択するかは、ユーザーがサービスに何を求めているかを理解することから始まります。例えば、検索サービスであればレイテンシが、データ保存サービスであれば耐久性が重要なSLIとなるでしょう。
■ SLOの設定と改善
SLIを定義したら、次にそれらのSLIに対する目標値(SLO)を設定します。SLOは、単なる技術的な目標ではなく、プロダクトやビジネスの状況を反映したものであるべきです。
SLO設定と改善のポイントは以下の通りです。
• 現実的な目標設定: 現在のシステムのパフォーマンスに基づいて安易に目標を設定するのではなく、システムのメリットと限界を理解した上で、ユーザーが満足するレベルを考慮して設定します。最初は緩めのターゲットから始め、システムの理解が進むにつれて厳しくしていくことが推奨されます。
• ビジネスとの連携: プロダクトマネージャーなどのステークホルダーと協力してSLOを規定し、ビジネス目標との整合性を図ります。
• エラーバジェットの導入: SLOに基づいてエラーバジェット(許容される障害の量)を算出し、これを通じて開発速度と信頼性のバランスを取りま。エラーバジェットの残量に応じて、新しいリリースの推進を判断するなどのコントロールループを構築します。
• SLOの文書化とレビュー: 設定したSLOとその背景にある根拠、エラーバジェットの計算方法などを明確に文書化し、定期的にレビューを行います。
• アラート戦略の策定: SLOに基づいて、重大なイベントを検知するためのアラート戦略を構築します。 適合率(precision)と再現率(recall)のバランスを考慮し、ノイズの少ない効果的なアラートを目指します。 低トラフィックなサービスに対するアラート戦略も検討が必要です。
■ 継続的な改善
SLI/SLOは一度設定したら終わりではありません。システムの変更、ユーザーのニーズの変化、運用実績のデータに基づいて、継続的に見直しと改善を行う必要があります。
• モニタリングと分析: 設定したSLIを継続的にモニタリングし、SLOとの比較を行います。 エラーバジェットの消費状況を分析し、信頼性向上のための優先順位付けを行います。
• インシデント対応とポストモーテム: SLO違反が発生した場合は、迅速に対応し、その根本原因を特定するためのポストモーテムを実施します。 ポストモーテムで得られた教訓をSLOやシステム設計に反映させます。
• フィードバックループ: ユーザーからのフィードバック、サポートチケットの状況などをSLI/SLOの妥当性を評価するための重要な情報源とします。
これらのアクションを通じて、現在の可用性SLIをより洗練させ、他の重要な側面を捉えるSLIを追加することで、より効果的なSLO運用とサービスの信頼性向上に繋げることができます。
もしよろしければ、現在どのように可用性を計測されているか、また、他にどのようなサービスレベルに関心をお持ちかなど、詳細を教えていただけますでしょうか。より具体的なアドバイスをさせていただけるかと思います。
めっちゃちゃんと打ち返してくれますよね!優秀優秀。
もう少し質問してみましょう。今度は実際に私が携わっているFanstaというサービスをもとに答えさせてみます。
Q. 「成功したリクエストの割合」を可用性として計測しております。サービスとしては、「店舗検索: ユーザーはエリア、試合日程、好きなチームなどの条件からスポーツ観戦ができる飲食店を検索できます」、「予約機能: ネット予約が可能で、試合上映時や通常営業時の集客力アップに貢献します」、「事前決済機能: 予約時にプラン金額を事前決済することで無断キャンセルのリスクを抑えます」といった機能があります。これらから考えられるSLIを挙げてください。
A.
現在「成功したリクエストの割合」を可用性として計測されているとのことですが、これは基本的ながらも重要な SLI です 。しかし、サービスの特性をより深く捉え、ユーザー体験の向上に繋げるためには、機能ごとのより詳細な SLI を検討することが推奨されます。
以下に、各機能から考えられる SLI の候補を挙げ、それぞれの根拠と計測のポイントを説明します。
1. 店舗検索:
• SLI 候補: 「条件に合致する店舗が検索結果として表示されたリクエストの割合 / 全店舗検索リクエスト数」
根拠: ユーザーが求める情報が得られたかどうかを直接的に測る SLI です。単なるリクエストの成功だけでなく、検索機能が意図通りに動作しているかを評価できます。
計測のポイント: 検索条件(エリア、試合日程、好きなチームなど)の種類に応じた成功率を個別に計測することも有効です。また、検索結果が返ってくるまでのレイテンシ(後述)と合わせて評価することで、より詳細な状況把握が可能になります。
• SLI 候補: 「店舗検索リクエストの平均レイテンシ」
根拠: 検索結果が表示されるまでの時間を測ることで、ユーザー体験における応答性を評価します。「高速」な検索はユーザー満足度に大きく影響します。
計測のポイント: 特定の条件下での検索(例:高負荷時、複雑な検索条件)におけるレイテンシの変化を捉えることが重要です。SLO を設定する際には、ユーザーが許容できるレイテンシの閾値を検討する必要があります。
• SLI 候補: 「エラーが発生せずに店舗検索が完了したリクエストの割合 / 全店舗検索リクエスト数」
根拠: エラーの発生率を直接的に計測し、サービスの安定性を評価します。
計測のポイント: HTTP ステータスコード(5xx エラーなど)やアプリケーション内部で発生するエラーをモニタリングします。
2. 予約機能:
• SLI 候補: 「予約リクエストが正常に完了した割合 / 全予約リクエスト数」
根拠: ユーザーが意図した予約操作が成功したかどうかを測ります。
計測のポイント: 予約完了を示す API のレスポンスや、予約情報のデータベースへの書き込み成功などを指標とします。
• SLI 候補: 「予約処理の平均レイテンシ」
根拠: 予約完了までの時間を計測し、ユーザー体験における応答性を評価します。
計測のポイント: 予約開始から完了までのAPI呼び出し全体の時間を計測します。
• SLI 候補: 「事前決済を伴う予約が正常に完了した割合 / 全事前決済を伴う予約リクエスト数」
根拠: 事前決済が予約フローに組み込まれている場合、決済処理を含めた予約の成功率を個別に計測することが重要です。
計測のポイント: 決済代行サービスのAPIレスポンスや、決済ステータスの確認などを指標とします。
3. 事前決済機能:
• SLI 候補: 「事前決済リクエストが正常に完了した割合 / 全事前決済リクエスト数」
根拠: 決済処理自体の成功率を測ります。
計測のポイント: 決済代行サービスのAPIレスポンスや、決済ステータスの確認などを指標とします。
• SLI 候補: 「事前決済処理の平均レイテンシ」
根拠: 決済処理にかかる時間を計測し、ユーザー体験における応答性を評価します。
計測のポイント: 決済開始から完了までのAPI呼び出し全体の時間を計測します。
• SLI 候補: 「決済エラーが発生したリクエストの割合 / 全事前決済リクエスト数」
根拠: 決済処理におけるエラーの発生率を計測します。
計測のポイント: 決済代行サービスからのエラーコードや、アプリケーション内部で発生する決済関連のエラーをモニタリングします。
■ SLI 選択の原則:
• ユーザーの関心事: ユーザーがサービスに対して何を期待しているかを理解し、それを反映する SLI を選択することが重要です。
• 計測の容易さ: 実際に計測可能であり、継続的にモニタリングできる SLI を選択します。既存のログやメトリクス基盤を活用することも有効です。
• シンプルさ: 複雑な集計を伴う SLI は、問題の原因究明を困難にする可能性があるため、シンプルな SLI から始めることが推奨されます。
• 網羅性: サービスの主要な機能をカバーするように複数の SLI を組み合わせることで、より包括的な信頼性の評価が可能になります.
次のステップ:
1. これらの SLI 候補の中から、貴社のサービスにとって最も重要なものをいくつか選択します。
2. それぞれの SLI に対して、具体的な計測方法を定義します。既存のモニタリングシステムで計測可能か、新たな仕組みが必要かを検討します。
3. 選択した SLI に基づいて、サービスレベル目標(SLO)を設定します。SLO は具体的なターゲット値または範囲で定義し、ビジネス目標と整合性があるようにします。
4. SLO 違反時のアクションを定義したエラーバジェットポリシーを策定します。
5. SLI、SLO、エラーバジェットポリシーを関係者間で共有し、合意を得ます。
ご提示の機能以外にも、例えば予約のキャンセル率や、特定期間におけるアクティブユーザー数なども、サービスの健全性を測る上で重要な指標となる可能性があります。これらの指標を SLI として検討することも有益でしょう。
これらの提案が、貴社のサービスの信頼性向上の一助となれば幸いです。何かご不明な点や、さらに深掘りしたい SLI がございましたら、お気軽にご質問ください。
きちんとSLI候補に対してのポイントも書いてくれているのがグッドですね。
こんな感じで、適切なソースを読み込ませることで優秀な壁打ち相手になってくれます。コレデ サミシクナイ。
今回はSLI/SLOに関することなので、SLO本を読み込ませるのも良いかもしれませんね。(PDF持ってなかった・・・)
このようにSREに関して汎用的に使えるノートブックを用意するのもいいですが、もしひとつの事柄に関してより詳細に詰めていきたい場合は(例えば今回のようにSLO)、該当するソースのみを読み込ませたノートブックを用意するのがよいかもしれません。
先述した通り、ノートブックに汎用性を追い求めて多種多様なソースを読み込ませると途端に回答精度が悪くなります。少し面倒ですが、用途別で細かくノートブックを作っていき、欲しい情報に合わせたソースを読み込ませるのが良いでしょう。
おわり
というわけで、今回はNotebookLMを使って一人SREの孤独を埋めるSRE壁打ちくんを作って使ってる話をしました。
これ以外にもNotebookLMは本当に優秀で、読むのに一苦労な資料も読みやすくすることができます。
まだまだ使い始めたばかりなので今後も使い倒し、もう一人のSREsとして頑張って働いてもらおうと思います!💪