オンコール運用を劇的改善!ツール導入で見つけた成功のカギ
自己紹介
こんにちは!ココナラでHead of Informationを務めているゆーたです!
SRE / 情シス / セキュリティ領域のエンジニアマネージャーで、SRE NEXT 2024のコアメンバーもしていました。 来年のSRE NEXT 2025もコアメンバーをしますので、ぜひプロポーザル応募やご参加をお待ちしています!
SRE Magazineに寄稿するのは2回目で、前回は「SIEMってサイトの信頼性向上に寄与するの?」という記事を書きました。 こちらもぜひご覧ください!
https://sre-magazine.net/articles/1/yuta_k0911/
オンコール運用との関わり
私がオンコール運用に携わるようになったのは、社会人歴6年目ぐらいです。 それまでは、「システム運用」の領域に携わることは多くなく、たとえば具体的な運用作業のオペレーション(本番サーバーの各種ログから情報収集・分析をする、負荷状況を調べる、など)に携わった経験はありません。 ※システム運用を専門にしている部署があり、本番環境作業はすべてその部署だけが権限を有して作業をしていたため、私を含めた開発者は触れませんでした
その当時のシステム運用・システム監視を外部業者に委託しており、インシデントが発生した場合にオンコール当番(1次受け)へ架電をしてもらい、そこから調査やトリアージを始める運用になっていました。 図にすると以下のとおりです。
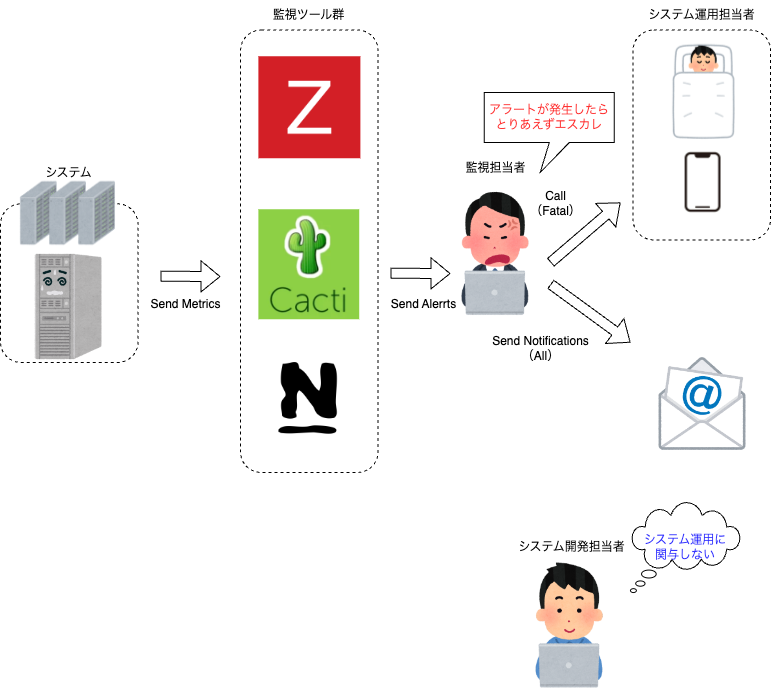
架電でインシデント発生を伝え、詳細はメールを確認する運用のため、対応のオーバーヘッドが大きい状態でした。 私はオンコール運用の「2次受け」に該当するチームにいましたので、アラート発生時に最初に連絡が来る役割ではなく、トリアージやワークアラウンド対応が一定済んだ後に出張る役割でしたが、調査や分析に時間を要していた記憶があります。
PagerDutyがなかった頃の世界
オンコール運用に限った話ではありませんが、昔はチャットツールが主流ではなく、仕事でのコミュニケーションは電話・メールが中心でした。 もちろんWeb会議の文化もまだまだ醸成されてはいない状況でした。私の所属していた部署では、重大インシデントの対応のためにオフィスへ向かったことも記憶にあります。
当時のコミュニケーションのやり方とオンコール運用を照らし合わせて考えると、以下の課題を抱えていました。
- メールでの情報だけでは、どこで・何が起きていて・どういうユーザー影響が発生しているか?を捉えきれない。
- インシデントが発生したことは理解できるが、現状把握だけでも時間を要する
- アラートが発生した時点で誰が対応に動いていて、どういう状況なのかがわかりにくい。
- 関係者に電話しても1対1の会話になるので、リアルタイムの情報共有1つを取っても難易度が高かった
- 万が一、同時に複数のインシデントが発生した場合のキャッチアップが難しい。
ここからPagerDutyの話に入ります。 ココナラでは、2016年まではAWSのメトリクス監視ツールからメールによる通知を利用したオンコール運用体制を採用していました。そのため、以下の課題が発生していました。
- 当日のオンコール担当者が誰かがわかりにくい
- アラートの通知がメールのみなので、オンコール担当者がアラートに気づけなかった or 気づいたが動けない場合のエスカレーションが滞り、アラート対応が遅れる
- ↑の結果として、MTTA(平均確認時間)は約10分程度と長くなってしまっている
それらに対しての打ち手を考えたときに「PagerDutyの導入」以外でも
- 外注による運用監視体制の構築
- Amazon Connectの利活用
- 内製(社内メンバーによる24時間,365日の監視体制)
がありましたが、基本的にコストが高く、サービスグロース中のココナラに導入することは難しいと判断できます。 その3案に対する検討結果をざっとまとめると以下の通りです。
- 24時間・365日の安定稼働を実現するには自社内の人手で対応するのは非現実的です。人手でオンコール運用に力を注ぐことはプロダクトのグロースが遅れてしまいます。
- Amazon Connectは当時QCDのバランスがあまり取れず、アドオンされる機能が少なかったので、採用は難しかったです。
- オンコール体制ごとアウトソースするには莫大なコストが掛かるので、さすがに払えません。
私の前職でも費用対効果を鑑みて、PagerDutyを採用していました。 もともとココナラの監視はAWSサービス以外のDatadogなどのサードパーティ監視ツールを活用していたため、それとの親和性も考慮した結果とも言えます。
PagerDutyとの出会い
ココナラのオンコール運用
ココナラでは2017年からPagerDutyを利活用したオンコール運用を実現しています。ポイントを以下に記載します。
- オンコール担当者は24時間交代で、毎朝10時にオンコールシフトを切り替える。
- オンコール当番はプライマリーとセカンダリーを設けており、主体的な対応者を明確化している。
- ただし、オンコール当番でないエンジニアもアラートが通知されるSlackチャンネルは常時通知をONにしており、フォローがしやすい体制を構築している
- 一定時間反応がなかった場合はプライマリーからセカンダリーへと自動でエスカレーションされ、セカンダリーも反応がなかった場合は各領域のエンジニアマネージャーに一斉にエスカレーションされる。
- オンコール当番の日は手当てが支給される。
ざっくりですが、ココナラのシステムとオンコール運用を図にしたものが以下です。
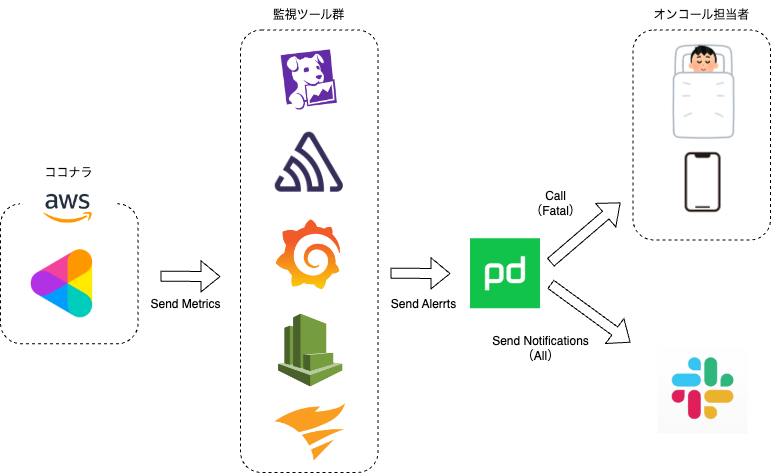
ココナラのプロダクトはAWS上で稼働しています。 そこを複数の監視サービスでメトリクスをモニタリングしており、異常を検知したら、PagerDutyを介してオンコール担当者へ電話もしくはSlackで通知する仕組みを採用しています。 また、重要度に応じて、Slackのみの通知とするか、架電するかを棲み分ける運用をしています。
オンコール運用の各論
以下を日々の運用の中で行っています。
- オンボーディング資料の拡充(PagerDutyの使い方含む)
- アラートの対処方法のナレッジ化(対応要否やバッチ処理のリランのやり方含む)
- 有識者と新任者のペアリングによるオンコール運用のスキルトランスファー
また、オンコール運用を効率的・効果的にするために一部自社開発しているので、ご紹介します。 これは私が着任したときから活用されているものなので、当時は類似機能がなかった、もしくは既存機能を認識していなかったと想像されるので、現在はPagerDutyに類似機能が存在しているものもあります。
1. 当日のオンコール担当者をSlackに通知
ココナラでは毎日10時にオンコールシフトを切り替えており、そのタイミングでSlackの特定のチャンネルに当日の担当者を通知しています。 自身のカレンダーに自分のオンコールシフトを連携している方が大多数ですが、当日のオンコール担当者が誰か?はPagerDutyの管理画面を見に行かないとわかりません。
これを自作することによって「今日は◯◯グループの△△さんね」「着任したばかりだから、アラートが鳴ったら対応できるときは声かけ合おうか」という組織で円滑なオンコール運用を実現することができます。 もちろん、自身がオンコール当番のときの認識漏れを防ぐことにも役立ちます。

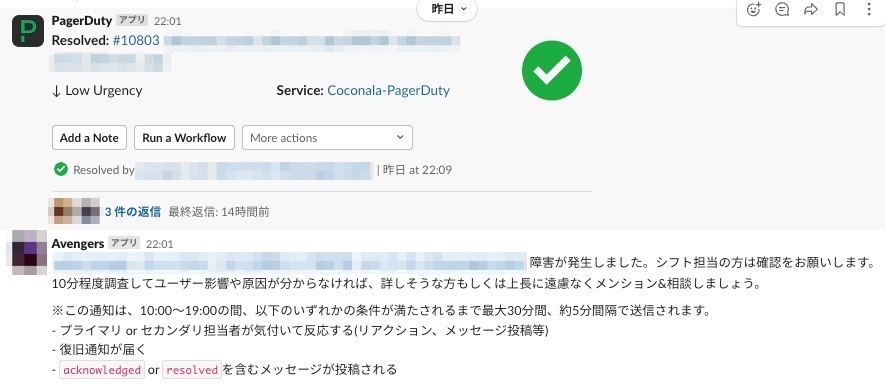
2. アラート発生時に当日のオンコール担当者へメンション
アラートが発生した際に、その日のオンコール担当者へSlackにメンションを行うことで、より気づきやすい仕組みを実現しています。 基本的にアラートが通知されるチャンネルは常に通知をONにしていますが、メンションがついている方がより見逃しが無くなるので、重宝しています。
また、オンコール担当者の反応が一定時間ないときにリマインド通知をしてくれる機能も作り込んでいるので、オンコール担当者以外も「あれ?オンコール担当者が反応できていない?フォローした方が良いね!」とアラートの未反応・未対応に気づきやすい仕組みとなり、結果としてMTTAが短くなるようにしています。
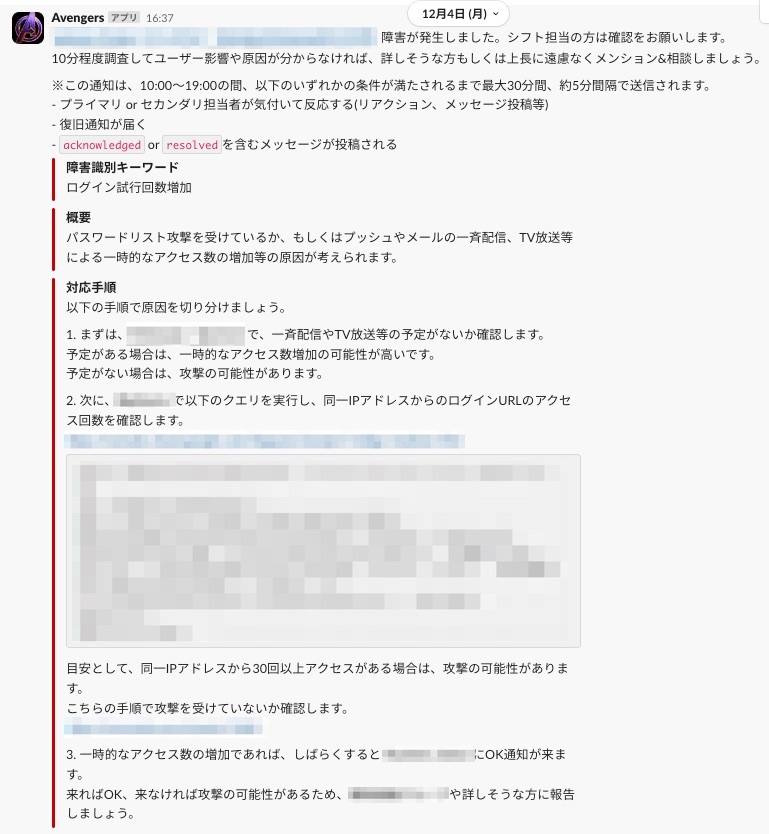
3. アラートのキーワードを元にRunbookを通知
既出のアラート、かつ、あらかじめRunbookを用意しているものに限定した仕組みなのですが、Slackに通知されたアラート内容からキーワードを抽出し、合致したものがある場合にRunbookをSlackに通知しています。 これによって、オンコール担当者は自分でRunbookを検索することなく、Slackを見るだけでこのアラートに対する対応要否、対応が必要な場合の手順が確認でき、インシデント対応を進めることが可能です。
アラート対応の大事な要素の1つは「落ち着くこと」と考えていますので、既出のアラートに対して対応をサジェストしてくれるこの機能は私としても、かなり重宝しています。
いろいろ書き連ねましたが、これらの対応にて MTTAを1分程度まで短縮する ことができています!🎉 PagerDutyがオンコール運用の要と言っても過言ではありません!
PagerDutyと出会ったことで、オンコール運用がどう改善したか?をQCD観点で振り返ってみます。
| 比較軸 / ツール | メール通知 | PagerDuty |
|---|---|---|
| Quality | ✕:アラートの通知のみで付加機能はなし | ◎:アラートの通知に加えて、付加機能(リマインド、各種インテグレーションによるアラート集約、インシデント管理との連携、など)を使えるようになった |
| Cost | ◎:メールなので、費用は安価 | △:PagerDutyの方が既存の仕組みよりは費用がかかった |
| Delivery | △:特に深夜、休日にアラートが発生するとMTTAが悪化したり、取りこぼしがあったりする | ◎:MTTAが大幅に改善した、自動・手動エスカレーションにより、今までよりも短時間で必要な人へエスカレーションが可能になった |
これからのオンコール運用のあり方
まずは「オンコール担当者が障害調査に集中できる」世界を作ることが大事です。 その手段として、PagerDutyのようなツールの利活用が重要な要素の1つと考えています。
ただし、ツールの機能を100%使い倒すことは正直なところ難しいです。 一方で、「新機能=利用者が欲しかったもの or 利用者のかゆいところに手が届くもの」という図式ですので、しっかり最新情報に追随していくというのは大事なポイントではないでしょうか。
次に24時間・365日で動いているサービスの前提として、「必要なタイミングに必要な人が動ける体制を構築する」ことが必要不可欠です。 「検知して対応する」という流れの中の「検知」の部分で、様々あるサードパーティの情報を全部まとめるというプロセスが第一歩目になると考えます。
そして、今後は機械学習やAIOpsがより利活用される状態になるのではないでしょうか? 「アラート」はビッグデータの1つとも言えます。そこを深堀りすることでインシデント内容やインシデント対応の傾向が見えてきます。 また、「デプロイ頻度」「施策リリースタイミング」など、様々なイベントとも突き合わせをすることで、何かしらのヒントがでてくる可能性もあります。
もしかしたら、「オンコール当番」によって、アラート数のトレンドが違うなどの非科学的な情報が見えてくるかもしれませんよ? ※◯◯さんが休暇や不在のときにやたらとインシデント多いよね…というのは、意外とあるあるではないでしょうか
私見ですが、現時点でPagerDutyを凌駕するオンコールに関するツールはないと考えています。 これからオンコール運用をどうしていくか?を検討している企業で1回も試さないのは損ですので、ぜひご検討ください。
一方で、PagerDutyを利用するうえでの課題もいくつかあります。
- 日本語ドキュメントの拡充
- 日本法人が新しく設立されたばかりということもあり、日本語のドキュメントがまだ少ない
- ただし、拡充されつつあるので、今後の期待大
- CSのサポートによるオンボーディングや伴走
- 新機能の紹介や、現時点で未利用の機能に対して、他社がどのように活用しているかなどのベストプラクティスをシェアしてくれる機会などがあると良い
- アラートの自動トリアージ機能
- 機械学習的なアプローチなどを用いて、「これは対処しなくてもいいです」と表示したり、自動でRunbookに追加されるなどの機能があると嬉しい
- また、新しいアラートや問題が発生した際に、それが以前に経験したことがないかどうかを識別して「これまでに出たことがないアラートです」のような表記ができるとより良い
これからオンコール運用を検討する方は「はじめの一歩」として、まずはPagerDuty利用企業の事例を参考にPoCなどに取り組むと良いのではないでしょうか。 会社によってオンコール運用の仕組みやルールはさまざまですが、この記事の内容が参考になれば幸いです。
Appendix
- 2023年のPagerDutyアドベントカレンダー記事:PagerDutyを活用したオンコール運用の軌跡
- PagerDuty Japan Community Meetup Vol.2登壇資料:PagerDutyを活用したオンコール運用の軌跡
- PagerDuty事例掲載:ココナラ
- Findy Tools:PagerDutyレビュー